Seguramente muchos de ustedes estarán pensando que tras esta entrada se esconde el humosoft o vaporware que tanto gusta en estos días, pero créanme que no hablaré de sinergia, aportar valor, retorno de la inversión ni de ninguna de esas coletillas que tan bien suenan pero que tan difíciles son de apreciar. En su lugar, vamos a explicar de forma sencilla que es realmente la correlación exponiendo sus ventajas e inconvenientes. De manera muy resumida ésta consiste en, dadas una serie de fuentes de información, ser capaces de obtener los datos más relevantes para nuestra infraestructura, así como ser capaces de detectar una acción que por si sola cada una de las fuentes de información no serían capaces de detectar. Aquellos datos relevantes correlados se notificarán mediante alertas a una consola centralizada.
Como ven hemos introducido un elemento adicional: la fuente de información. Pero, ¿qué es realmente y que tipo de fuente nos interesa? La fuente de información no es más que “un algo” que aporta información al correlador de los acontecimientos ocurridos en nuestra infraestructura. Por ejemplo una herramienta de detección de intrusos, monitorización de los recursos, registros de un servidor, control de acceso físico, estación meteorológica, etc. Cuanto más fuentes de información dispongamos y cuanto más distinta sea la información aportada por cada una de éstas respecto al resto de ellas mejor visión de los acontecimientos tendrá el correlador, y por tanto, mejor funcionará. Como verán no nos interesa tener veinte fuentes de información que aporten casi lo mismo sino tres que aporten información totalmente distinta.
Una vez disponemos de las fuentes de información, se deben crear una serie de reglas de correlación que sean capaces de extraer la información realmente relevante de todo el conjunto de hechos notificados. Efectivamente durante dicho proceso es posible que perdamos acontecimientos que realmente son interesantes para nuestra infraestructura, pero deben entender que al final se trata de un equilibrio entre las alertas y los recursos disponibles. El objetivo es minimizar la perdida de dichos acontecimientos dado el personal disponible. Veámoslo con un ejemplo sencillo donde una infraestructura genera 100.000 alertas diarias y se dispone de 5 técnicos para gestionarlas, es decir, 20.000 alertas para cada técnico. Si yo se que un técnico es capaz de tratar de media 100 alertas en un día ¿qué sentido tiene que yo cree un conjunto de reglas que sean capaces de detectar todos los acontecimientos relevantes en la infraestructura, si como resultado se generan 2000 alertas correladas diarias por técnico? ¿Para que se amontonen?
Es en este punto donde radica la dificultad de las reglas de correlación, puesto que se debe buscar un equilibrio entre el número de alertas correladas y los recursos de los que disponemos intentando minimizar el número de falsos negativos. Dichas reglas, independientemente de si procesan datos de una fuente de información o de varias, se suelen clasificar como simples, complejas y mixtas:
- Las reglas simples son aquellas que generan una alerta correlada a raíz de los acontecimientos notificados por la fuentes de información.
- Las reglas complejas son aquellas que generan una alerta correlada a raíz de las alertas generadas por otras reglas simples o complejas. También se suelen llamar reglas en cascada.
- Las reglas mixtas son aquellas que usan datos tanto de los acontecimientos notificados por las fuentes de información como por alertas previamente correladas.
Por tanto a la hora de implantar un entorno de correlación es importante tener en cuenta qué fuentes de información disponemos, como de diferentes son entre sí, qué cantidad de alertas se generan en el entorno y qué recursos de personal dispone un cliente. Una vez dispongamos de esta información procederemos a la creación de reglas simples, complejas y mixtas que empleen una única fuente de información y de otro grupo de reglas que empleen más de una fuente de información.
Veamos un ejemplo de cada una de ellas en un entorno donde disponemos de tres fuentes de información distinta compuestas por un entorno de monitorización, un gestor de logs del servidor y una herramienta de detección de intrusos:
- Monitorización: caída de un host que se encuentra en el listado de host del dominio protegido da lugar a un evento en la consola centralizada y el envío de un SMS a los administradores.
- Logs del servidor: autenticación del usuario administrador en un servidor en horario fuera de oficinas genera un evento en la consola centralizada del área de seguridad.
- Detección de intrusos: se detecta alertas de tipo SCAN referente a escaneo de puerto y posteriormente se detecta un ataque en menos de 1 hora desde la misma IP, lo que implica un ataque y por tanto evento. De esta forma solo tendremos en cuenta las alertas de SCAN cuando se detecte un ataque posterior.
- Monitorización y detección de intrusos: se detecta una alerta de denegación de servicio contra un servidor web y posteriormente se detecta la caída de dicho servicio. Ahora podemos tener en cuenta que la caída del servicio haya podido ser debido a un ataque de denegación de servicio.
- Monitorización y logs del servidor: se detecta la autenticación del usuario X en un router y posteriormente la caída de los dispositivos conectados a una de las interfaces del router.
- Detección de intrusos y logs del servidor: alerta de ejecución de una vulnerabilidad y posteriormente se notifica de la creación de un nuevo usuario en el servidor.
Como ven dada únicamente tres fuentes de información distintas las posibilidades de creación de reglas de correlación son prácticamente infinitas:
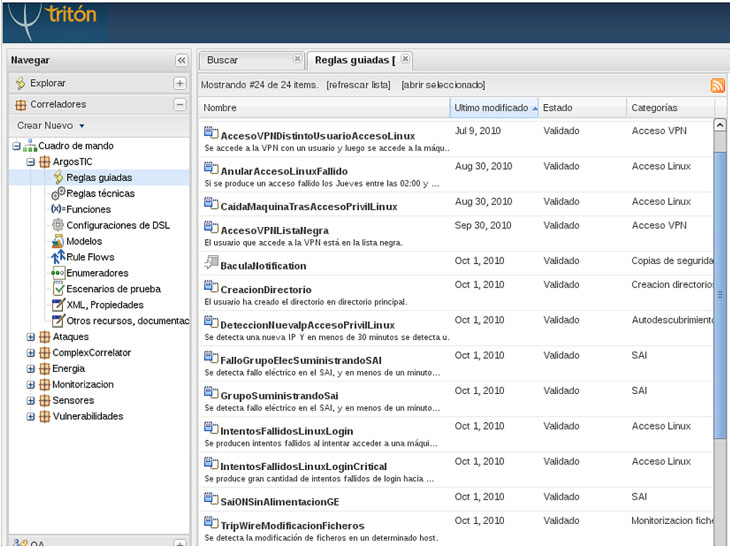
Para finalizar expondremos un ejemplo de nuestro correlador Tritón donde dada dos fuentes de información del mismo tipo, detección de intrusos, se han creado 8 reglas de correlación simples, 13 reglas de correlación compleja y una tabla de decisiones para la clasificación inicial:
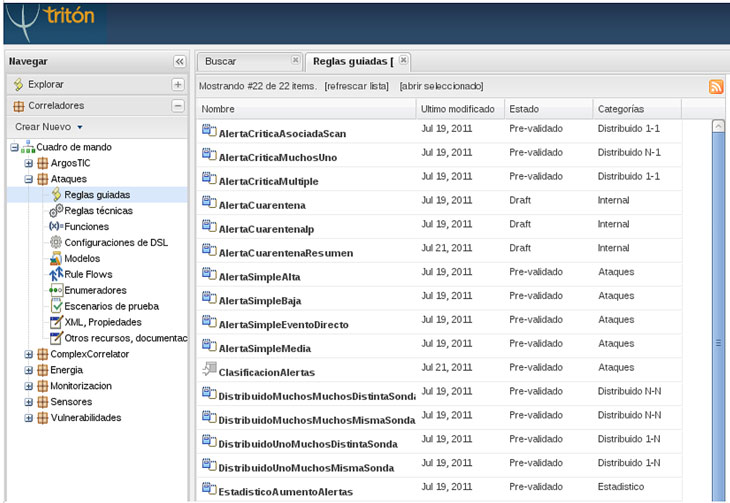
Empleando dichas reglas se procesaron un millón y medio de alertas durante dos meses notificando 8.000 alertas en la consola centralizada, lo que viene a ser unos 133 eventos al día, frente a las 25.000 alertas diarias generadas por las sondas de detección de intruso. De dichas 133 eventos aproximadamente 65% corresponden a reglas de correlación simples y el 35% corresponde a reglas de correlación complejas: