
En entradas previas hemos visto qué era UMO y una pequeña guía de cómo instalarlo, por lo que ha llegado el momento de ver algunos ejemplos de cómo usarlo y donde puede ayudarnos.
Antes de empezar me gustaría comentaros que se han eliminado los ficheros de la sección de descargas donde estaba la versión empaquetada en tar.gz y es necesario por el momento descargarlo vía un cliente de subversión, tal que así, “svn checkout http://umo.googlecode.com/svn/ umo-read-only”. Añadir también que si os encontráis problemas en el uso de la librería MySQLDb con la librería para Safebrowsing en python, deciros que he propuesto un pequeño cambio en el issue 11 del proyecto para que no dé problemas.
Antes de empezar, es aconsejable actualizar la base de datos con el siguiente comando:
$python umo.py --update-safebrowsing
Google SafeBrowsing Database- Update finished
También, aprovecho para recordaros que como muchos ya sabéis los logs son nuestros amigos, es por ello que he intentado que exista la mayor cantidad de información en ellos, de modo que permita detectar problemas en la aplicación, registrar las acciones de qué va realizando, los enlaces que procesa, etcétera. Cuando ejecutemos UMO tendremos varios logs (es posible cambiar el nivel de log, en el fichero de configuración):
- umolog.log: donde se registran mensajes relacionados con el funcionamiento de la aplicación, por donde va pasando, etcétera
- umourls.log: donde registro las URLs que UMO va procesando.
- umomalware.log: fichero donde se almacenan las urls con malware.
Vale, ahora sí, ha llegado el momento de algún ejemplo de uso. Para ello plantearemos dos casos donde podemos utilizar la herramienta:
1. Organización que dispone de una aplicación Web y quiere de manera periódica monitorizarla. En este caso decidimos recopilar mediante crawling los enlaces y comprobar si esos enlaces están registrados en el base de datos de Google SafeBrowsing que disponemos en local.
# Vamos a recopilar los enlaces de la web www.ejemplo-umo.es con nivel de profundidad 1:
$python umo.py --safebrowsing -H -u 'http://www.ejemplo-umo.es' -d 1
UMO crawler started ... waiting please, this task could take minutes
UMO Crawling done!
UMO is searching in Google Safebrowsing Database ... waiting
UMO finish! Review file for more information: umomalware.log , if it's empty, Congratulations :-)
Si queremos ver qué enlaces ha procesado, lo tendremos en umourls.log:
$ head -10 umourls.log
2011-11-09 12:45:04 : New Google SafeBrowsing Search started
http://www.ejemplo-umo.es/paginas/actualidad.html
http://www.ejemplo-umo.es/paginas/aviso-legal.html
http://www.ejemplo-umo.es/formacion/introducci%25C3%25B3n-al-vino.html
http://www.ejemplo-umo.es/formulario/informar-de-un-vino.html
http://www.ejemplo-umo.es/noticias/bolet%25C3%25ADn-quincenal.html
http://www.ejemplo-umo.es/formacion/curso-b%25C3%25A1sico-de-vino.html
http://www.ejemplo-umo.es/formacion/cata-de-vino.html
...........
En este caso concreto el fichero umomalware.log se encuentra vacío, lo que es una buena noticia. Deberemos tener monitorizado este fichero y en el caso de que se inserte un enlace que salte una alerta en nuestros sistemas.
2. El otro escenario que vamos a ver sería un ejemplo de un equipo de seguridad que quiere investigar determinada amenaza. Este escenario ha sido elegido para poder obtener resultados de páginas que se encuentran en la base de datos y por tanto están infectadas o lo han estado. En este caso no vamos a hacer crawling, sino que vamos a aprovechar que otros ya lo han hecho. La búsqueda que vamos a utilizar recoge los resultados de la infección masiva donde se inyectó el dominio “http://lizamoon.com”:
$python umo.py -g -q 'src=http://lizamoon.com/ur.php'
UMO Google Scanner will skip the first 10 pages...
Querying Google Search: 'src=http://lizamoon.com/ur.php' with max pages 10...
UMO is searching in Google Safebrowsing Database ... waiting
Url Malware OWNED, look at report: umomalware.log
UMO finish! Review file for more information: umomalware.log , if it's empty, Congratulations :-)
Enlaces recogidos por UMO y después los vulnerables:
$ cat umourls.log | wc -l
441
$cat umomalware.log | wc -l
20
En este caso vemos como parece que ha habido 20 URL’s de las indexadas que se ha encontrado en la base de datos.
http://www.urlindexada1.es/index.cfm?url=&video_id=27&page_display=36&page=1&&searchbox=&country_name=
http://www.urlindexada2.es/BusinessM.aspx
http://www.urlindexada3.es/forum/
http://www.urlindexada4.com/thai/trader/real_estate/index.asp?s_id=987
http://www.urlindexada5.co.uk/page.asp?id=buslpul
http://www.urlindexada6.com/developmentdetails.aspx?did=2
http://www.urlindexada7.com.cn/SaleTicket/Show.asp
http://www.urlindexada8.com/index.cfm?url=&video_id=78&page_display=36&page=1&&searchbox=&country_name=
http://www.urlindexada9.it/articles.asp?id=10
http://www.urlindexada10.com/index.cfm?url=&video_id=98&page_display=36&page=1&&searchbox=&country_name=
http://www.urlindexada11.com/viewpost/8371/forum/forum/
http://www.urlindexada12.es/sjournal/eng/abstract.asp?sjid=2&issueid=49&contentid=357
............
Tomando como ejemplo uno de los enlaces y viéndolo con la herramienta Malzilla, vemos como contiene código inyectado (pinchar sobre la imagen para ampliar):
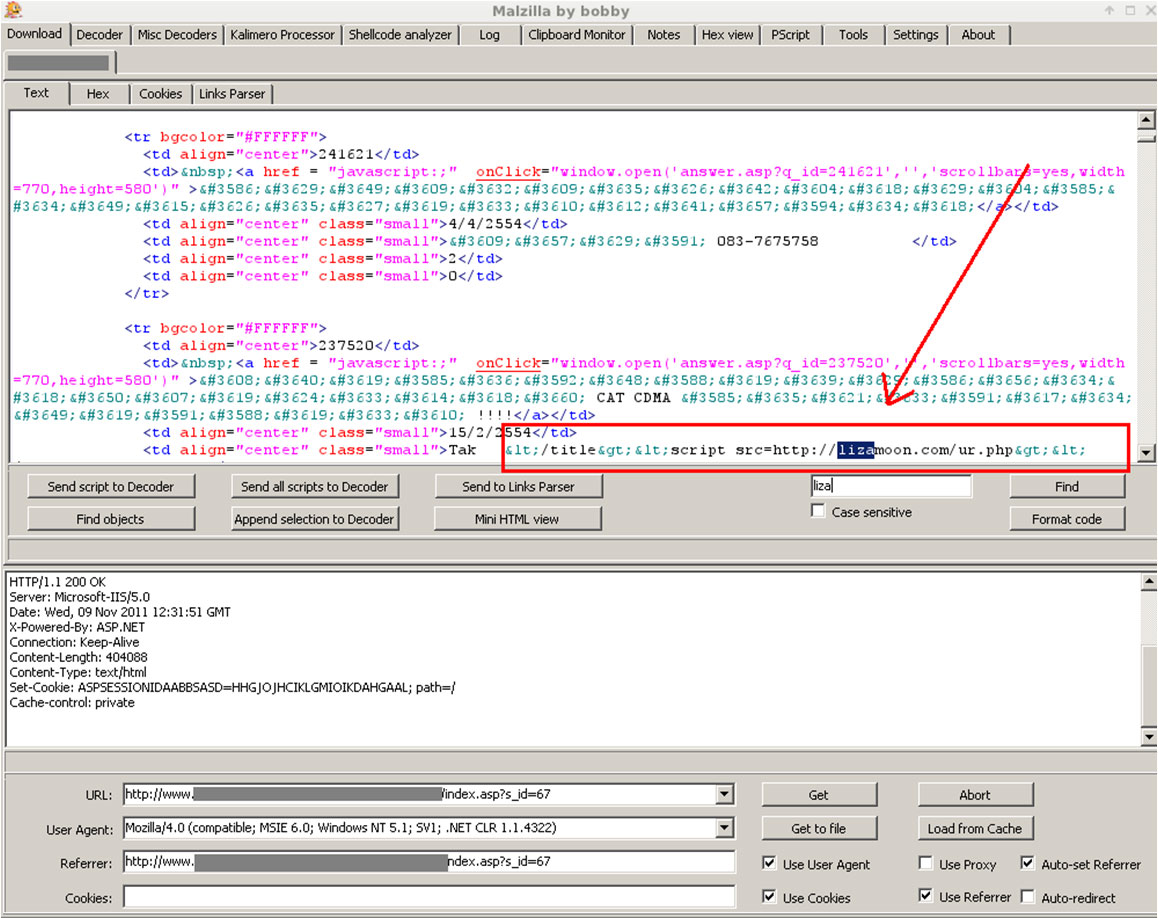
Comparando los dos casos, hemos visto que el modo que utilizan los principales buscadores tiene como ventaja que no actúa de manera directo sobre el objetivo, pero tiene como principal desventaja que la información nos la ofrece un tercero y debemos ver que no esté “sesgada” o limitada, por cantidad de peticiones u otros factores. En cambio, el modo que realiza crawling directo sobre el objetivo, ofrece como principal ventaja que no dependemos de un tercero y como desventaja, en el caso de Webs de terceros, que es más intrusivo y ruidoso.
Como veis la herramienta es sencilla de utilizar (o eso espero) y al tratarse de un script podemos automatizar su uso. Para acabar, deciros que espero que esta entrada sirva para conocer un poquito más a UMO y recordaros por un lado que está en estado Beta y que cualquier comentario será bienvenido.