
Uno de los operadores que más me gusta a la hora de definir filtros con Wireshark es “matches“. Con este operador podremos extender las limitaciones que nos ofrece el resto de filtros a la hora de localizar determinados patrones en nuestros ficheros pcap. De forma parecida a “contains”, el operador “matches” nos permite buscar por determinadas cadenas de texto así como bytes con la ventaja adicional de soportar PCRE (Perl-compatible regular expression). Este operador será realmente útil a la hora de buscar gran variedad de ataques como DDOS, fuzzing, opcodes que coincidan con ciertos patrones de malware conocido, o, como veremos a continuación, exploits que se aprovechan de un stack/heap overflow.
Aunque obviamente Wireshark no es la herramienta más apropiada para detectar BO, en ocasiones en las que no tengamos a mano un Snort o los GSoC plugins vistos en la entrada anterior de Maite y nos enfrentemos a un .pcap de gran tamaño, disponer de macros que identifiquen ataques de este tipo puede ayudarnos enormemente en nuestra labor forense.
Los siguientes ejemplos representan el esqueleto típico de un buffer overflow, bien aprovechándose del RET address o del SEH (Structured Exception Handling):
payload = junk + eip + egghunter + nops + egg + shellcode payload = string + buffer + egg + shellcode + eip + nops + egghunter payload = junk + egg + shellcode + eip + nops + egghunter payload = junk + eip + nops + shellcode payload = junk + egg + shellcode + junk1 + nseh + seh + nops + egghunter + junk2 payload = nops + shellcode + nops + eip + nops + farjump + nops payload = junk + nseh + seh + nops + shellcode + junk1
Teniendo en cuenta estos ejemplos, podríamos definir un filtro que busque por paquetes que contengan un string largo (junk) formado por 0x4141414141, 0x9090909090 (NOPs) o similares e ir jugando con diferentes longitudes de cadena. Por ejemplo:
Podemos omitir \\1 si lo que buscamos son cadenas alfanuméricas de gran longitud comúnmente empleadas por herramientas de fuzzing o por scripts para calcular el offset del return address como la generada por pattern_create.rb (Aa0Aa1Aa2Aa3A…c1Ac2Ac3Ac4A….). Puesto que dicho filtro puede generar numerosos falsos positivos podemos ir un poco más allá:
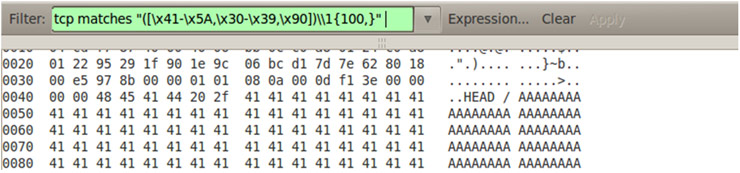
tcp matches "([\x41-\x5A,\x30-\x39,\x90])\\1{100,}.*((W00TW00T|w00tw00t|\x66\x81\xca\xff\x0f\x42\x52\x6a\x02\x58\xcd\x2e)|(\xeb\.\x90\x90|\x90\x90\xeb.|([\x61]){5}))?"
En este caso buscaríamos un buffer superior o igual a 100 seguido de lo que sea (.*), seguido de w00tw00t (generalmente utilizado como egg para definir el comienzo del shellcode) o seguido del propio código del egghunter (12 primeros bytes). Los siguientes opcodes \xeb\.\x90\x90 y \x90\x90\xeb. suelen utilizarse cuando lo que está sobrescribiendo es algún campo nSEH dentro de la cadena SEH (chain SEH). Generalmente el registro SEH será sobrescrito por alguna instrucción que permita saltar al campo nSEH (situado justamente detrás).
Dependiendo de donde se encuentre el shellcode (bien delante o bien detrás de la estructura SEH) será necesario hacer un salto positivo o negativo, de ahí que únicamente se especifique el opcode EB (short jump) sin especificar que tipo de salto y cuantos bytes se desean saltar. Al final, también se busca por opcodes x61 (popad) consecutivos, utilizados también como recurso para desplazar el registro ESP hasta el shellcode. En el siguiente ejemplo se muestra un intento de BO contra un servidor HTTP utilizando la cabecera HEAD.
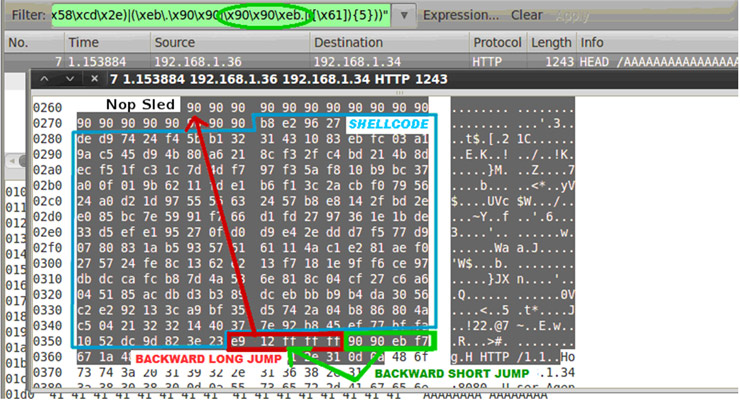
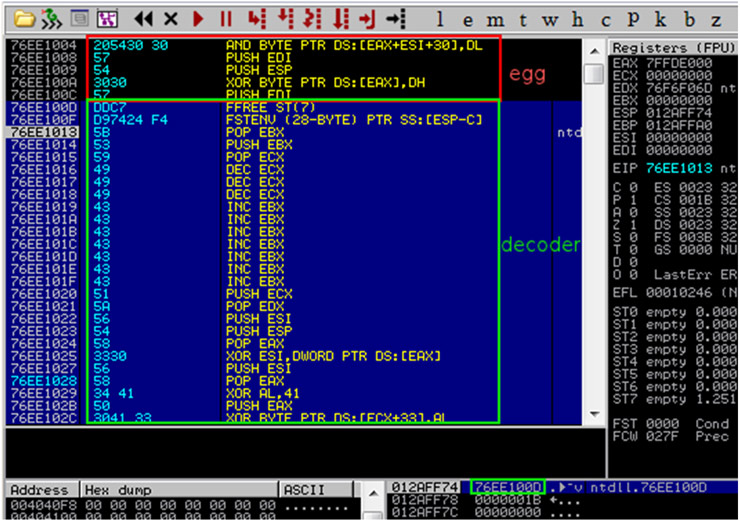
Veamos otro ejemplo. En este caso crearemos un filtro que detecte un BO que utiliza un shellcode o egghunter codificado con x86/alpha_upper. Al igual que otros encoders, alpha_upper es relocalizable en memoria. Esto significa que es capaz de obtener la dirección base absoluta de su propio código, lo que le permite ejecutarse independientemente de su posición en memoria. Para poder obtener la dirección absoluta de memoria utiliza instrucciones FPU (Floating Point) junto a FSTENV.
Cuando se emplea esta técnica como GetPC (Get Program Counter), se suele utilizar una instrucción de coma flotante al inicio del decoder junto a la instrucción FSTENV PTR SS: [ESP-C] encargada de almacenar el entorno FPU en memoria. De esta forma se consigue cargar la dirección de la primera instrucción en el stack para posteriormente descargarla en algún registro (ver figura 4). Utilizando un offset realativo a esta dirección, podrá empezar a decodificar el resto del payload. Teniendo en cuenta este comportamiento, si nos fijamos en la forma que toman los payloads generados por msfencode pueden observarse ciertos patrones comunes en los primeros opcodes:
Payload1= “\x89\xe0\xda\xc9\xd9\x70\xf4\x5a\x4a\x4a\x4a\x4a\x4a\x43\x43" + ...
Payload2= “\xd9\xc6\xd9\x74\x24\xf4\x58\x50\x59\x49\x49\x49\x43\x43\x43” + ...
Payload3= “\xda\xdd\xd9\x74\x24\xf4\x5d\x55\x59\x49\x49\x49\x43\x43\x43” + ...
Payload4= “\xdb\xd7\xd9\x74\x24\xf4\x5b\x53\x59\x49\x49\x49\x43\x43\x43” + ...
Payload5= “\xdd\xc2\xd9\x74\x24\xf4\x5b\x53\x59\x49\x49\x49\x43\x43\x43” + ...
Los opcodes d9, da, db y dd forman parte de instrucciones FPU como FXCH, FFREE, FCMOVU mientras que los opcodes \xd9\x74\x24\xf4 representan FSTENV PTR SS: [ESP-C]. En el primer caso, se usa una instrucción mov, seguido de una instrucción FPU seguido de FSTENV. Puesto que el payload generado tiende a seguir alguna de estas secuencias podríamos general el siguiente filtro:
tcp matches "([\x41-\x5A,\x30-\x39,\x90]){100,}.*(\x89...\xd9.\xf4[\x30-\x5f]{7}\x43)|((\xd9|\xda|\xdb|\xdd).\xd9\x74\x24\xf4[\x41-\x5F]{8}\x43)"
Nota: fíjese que algunos de los opcodes del principio del decoder no son alpha uppercase, es decir, están fuera del rango [\x41-\x5A,\x30-\x39]; por este motivo se especifica [.] (cualquier byte).
En el siguiente caso se muestra la vista “Follow TCP Stream” de un paquete que ha ‘matcheado’ dicho filtro. La salida muestra un intento de explotación contra un server FTP (Filezilla) en el que se utiliza un payload codificado con alpha_upper y que trata de aprovecharse del parámetro PASS.
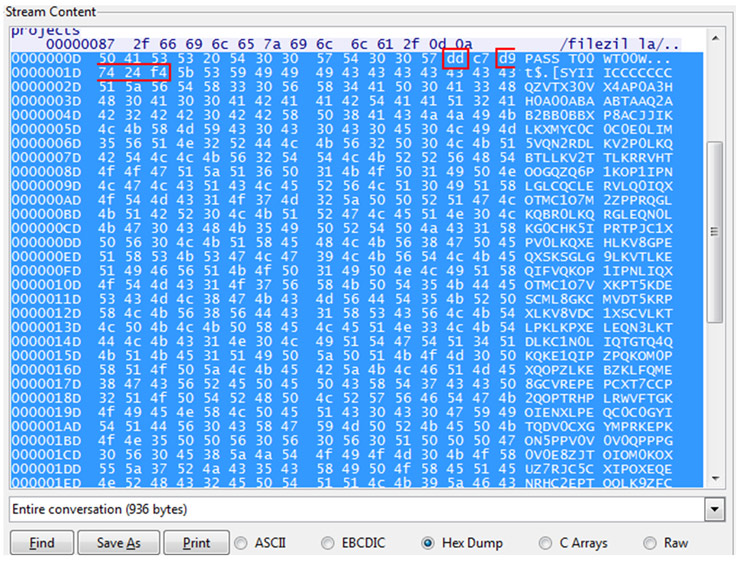
Si quisiéramos llevar este payload a Inmunity Debugger para una análisis más exhaustivo necesitamos eliminar espacios y añadir únicamente los opcodes.
root@Mordor:~# cat shellcode | cut -d" " -f 2-19 | tr -d "\n "
50415353205430305754303057ddc7d97424f45b535949494943434343434343515a565458333056583441
5030413348483041303041424141425441415132414232424230424258503841434a4a494b4c4b584d594
3304330433045304c494d3556514e3252444c4b563250304c4b5142544c4c4b563254544c4b5252564854
4f4f47515a513650314b4f503149504e4c474c4351434c4552564c51304951584f544d43314f374d325a505
05251474c4b514252304c4b5152474c45514e304c
[...]
Con este output y mediante la opción binary copy ya podemos pegar y empezar a analizar el código.
Para no tener que escribir el todas las expresiones regulares cada vez que arranquemos Wireshark, podemos guardarlas desde el menú Analyze -> Display Filters.
Obviamente las formas que puede tomar un BO son muy dispares y el uso de encoders más polimórficos como shikata_ga_nai dificultarán enormemente la localización de este tipo exploits mediante firmas estáticas. El objetivo únicamente es mostrar la flexibilidad que nos proporciona “matches” gracias a PCRE para localizar gran variedad de ataques como los vistos anteriormente siempre y cuando sigan algún patrón conocido. Por ejemplo, en el análisis llevado a cabo por McAfee sobre Aurora se indicaba como el backdoor iniciaba una conexión con el puerto 443 del C&C enviando siempre un paquete con la misma secuencia: ff ff ff ff ff ff 00 00 fe ff ff ff ff ff ff ff ff ff 88 ff. Con este dato podríamos definir un filtro en busca de paquetes que utilicen dicho payload sin necesidad de utilizar un IDS como Snort o esperar a que se actualicen sus reglas.
Para acabar, indicar que actualmente el operador “matches” presenta algunos problemas cuando se emplean metacaracteres y dígitos en hexadecimal con 2 letras. Si se necesita ‘matchear’ secuencias que contengan dichos bytes es necesario parchear epan/ftypes/ftype-pcre.c activando el flag G_REGEX_RAW. También me he encontrado con problemas a la hora de crear macros con dicho operador, algo que sería bastante útil para poder especificar como parámetro la longitud del buffer. Es decir, el filtro $buffer{200} para la macro tcp matches “([\x41-\x5A,\x30-\x39,\x90]){$1}” no funcionará cuando se empleen secuencias de bytes.