
 Los ataques de SQL-i siguen con nosotros. Por ejemplo, hace unos días un hacker hizo uso de esta técnica para obtener los contratos entre la compañía CEIEC y el Ministerio de Defensa chino.
Los ataques de SQL-i siguen con nosotros. Por ejemplo, hace unos días un hacker hizo uso de esta técnica para obtener los contratos entre la compañía CEIEC y el Ministerio de Defensa chino.
Debido a su criticidad y efectividad, el peligro que suponen los ataques de Inyección de Código SQL ha ido creciendo frente a otro tipo de amenazas hasta situarse como la principal amenaza para las aplicaciones Web (en lucha encarnizada con los ataques Cross-Site Scriptings XSS).
El rápido crecimiento de la oferta de servicios a través de Internet ha generado un amplio abanico de aplicaciones que, en su mayoría, utilizan bases de datos para almacenar y proporcionar la información.
El riesgo inherente en este tipo de aplicaciones es que durante la entrada de datos por parte del usuario,se manipule la consulta legítima a la base de datos y se genere otro código manipulado, permitiendo acceder a información de la base de datos o eludir la autenticación. Pero como la mayoría de ustedes ya saben que son los SQL-i, vamos a pasar a lo que interesa: nuevas técnicas para prevenirlos.
Basándome en un paper que leí el otro día, voy a exponer algunas de las técnicas que están siendo objeto de estudio por parte de diversos investigadores y desarrolladores para defenderse de los temidos ataques SQL-i:
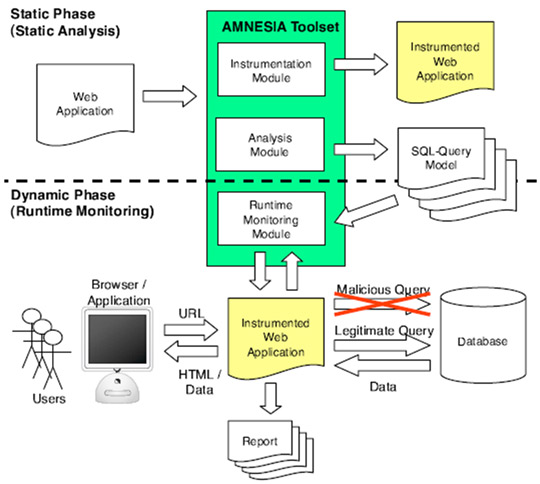
- El primer análisis [Halfond & Orso] se apoya en dos de las técnicas que otros estudios promueven: el análisis estático y el análisis dinámico del código. Para ello han desarrollado una herramienta llamada AMNESIA (Analysis and Monitoring for NEutralizing SQL Injection Attacks). Ésta efectúa un análisis previo del código de la aplicación, construyendo un modelo con las consultas legítimas que podrían ser generadas por la aplicación. Seguidamente, en tiempo de ejecución de la aplicación Web, se monitorizan las sentencias SQL generadas y, antes de ser interpretadas por la base de datos, son cotejadas con las consultas recopiladas. Aquellas que no cumplen con el modelo, son automáticamente rechazadas. Incluso notifica a los desarrolladores de su detección. Según las pruebas de los investigadores, esta técnica (con limitaciones de lenguaje y entorno), ha detectado todos los intentos de SQL-i sin generarse ningún falso positivo. Pueden ver un esquema de esta técnica en la imagen siguiente.
- La segunda técnica [Scott & Sharp] se basa en el uso de un Proxy para filtrar los datos de entrada y salida de la aplicación, basándose en una serie de reglas predefinidas y orientadas según las necesidades y el comportamiento de la aplicación web. También proponen crear una lista precompilada de consultas que eviten que las mismas necesiten ser generadas de forma dinámica.
- Otra propuesta [Huang & colleagues] es el testeo directamente sobre el software mediante la herramienta WAVES (Web Application Vulnerability and Error Scanner), la cual utiliza tanto técnicas de auditoría de caja negra (observación desde el punto de vista de un intruso externo), como de monitorización de comportamiento, análisis dinámico, ingeniería inversa e inyección de fallos (Fault Injection) para realizar la búsqueda de posibles vulnerabilidades de SQL-i en una aplicación web.
Como modelo de detección se utiliza la técnica de Fault Injection, analizando la salida resultante de aplicar patrones de Inyección SQL especialmente preparados, con un modelo de análisis basado en la técnica de auditoría de caja negra. Pero, antes de poder crear dicho patrones, es necesario aplicar técnicas de ingeniería inversa a la aplicación. Con este propósito, se realiza un reconocimiento completo de la web mediante un crawler, detectando, por ejemplo, puntos de entrada de datos de la aplicación.
El punto diferencial de este modelo es el uso de técnicas de aprendizaje automático durante las pruebas, a través de las cuales va creando una base de conocimiento que le permite ajustar los patrones de inyección a la propia aplicación de forma dinámica.
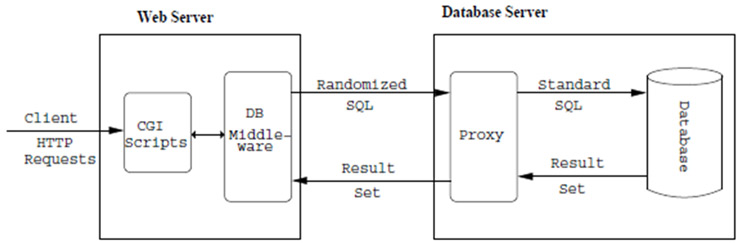
- La aproximación propuesta por otros investigadores [Boyd & colleagues] se basa en realizar un random de las consultas. Básicamente se trata de generar una serie de palabras clave típicamente utilizadas en las sentencias SQL (select, group by, where, from, or …) y “cifrarlas” mediante un algoritmo y una clave. Pero para que estas consultas aleatorias sean interpretadas por la base de datos, deben ser “descifradas” por un sistema proxy, único conocedor de la clave. De esta forma, la inyección de código SQL estándar por parte de una atacante, no puede ser interpretado por la base de datos, ya que el proxy no entiende ese lenguaje y descarta la consulta. Un esquema del funcionamiento de la técnica utilizando la herramienta SQLrand seria el siguiente:
- Una quinta técnica propuesta por dos grupos de investigación [Nguyen-Tuong & colleagues] y [Pietraszek & Berghe] sugieren la modificación del intérprete de PHP de serie para la detección del código dañino introducido por un usuario malintencionado. Esta técnica detectaría y rechazaría las queries sospechosas mediante un análisis exhaustivo de la entrada de datos, detectado aquellas que tratasen de crear cierto tipo de sentencias SQL. Además, se restringirían al máximo la estructura de la sentencia para que las variables fuesen mínimas y controladas (por tipo de dato, por el entorno, etc…).
- Un último enfoque [Valeur & colleagues] propone el uso de Sistemas de Detección de Intrusos (IDS) para detectar ataques de SQL-i. Este sistema estaría basado en un IDS con un aprendizaje automático a través de un conjunto de consultas legítimas a varios sistemas. De esta forma, construiría una serie de modelos de consultas lícitas y podría filtrar, en tiempo de ejecución, aquellas queries que no correspondiesen a ningún modelo. Como toda técnica basada en procesos de aprendizaje e inteligencia artificial, la generación de falsos positivos, sobretodo en las primeras etapas, sería inevitable.
Comprobando las tendencias de las nuevas técnicas, puede deducirse que se está tratando de encontrar el punto de compromiso entre la gestión dinámica y estática de la generación de las consultas SQL, recopilando sus ventajas y evitando los riesgos inherentes en cada una de ellas. ¿Podría decirse que nos encontramos en las puertas de una nueva generación en cuanto a la gestión de los datos en los entornos Web? Quizá. Pero el camino por recorrer será largo y costoso: una ardua tarea por parte de analistas y programadores, una larga convivencia de los diferentes modelos, migraciones y rediseño de las aplicaciones actuales…
¿Se os ocurre algún problema más?
(Fotografía del blog de RomanCortes.com)