
Some time ago we wrote about HoneySpider 2.0 and we made a quick look at its functionalities. Now let’s see one of the key pieces of this new version: workflows. We assume you have already installed HoneySpider 2.0 or that you are using the virtual machine provided by the project.
Given that we already have the application installed, first of all we have at hand the necessary documentation to define a workflow, which can be found here and here.
A workflow in HoneySpider 2.0 is composed of a series of processes, where each process is composed of services. These services contain input parameters and the ability to redirect its output to other processes. Let’s see a conceptual scheme of what is a workflow:
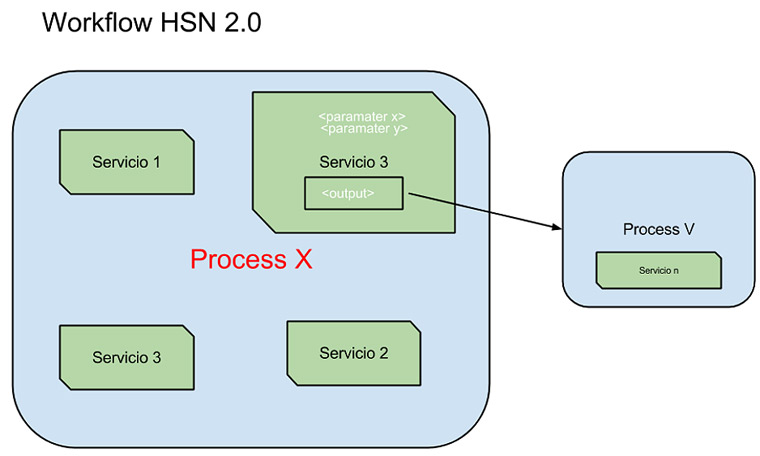
These workflows are defined in XML format. The following example will provide you with a very simple example workflow that performs a file analysis with rb-officecat (Nugget razorback) of the Office documents located in a set of web links:
<?xml version="1.0"?>
<workflow>
<description>
Analyze files office files with officecat
</description>
<process id="main">
<service name="feeder-list" id="feeder">
<parameter name="uri">/tmp/file.txt</parameter>
<parameter name="domain_info">true</parameter>
<output process="process_url"/>
</service>
</process>
<process id="process_url">
<service name="webclient" id="webclient0" ignore_errors="DEFUNCT">
<parameter name="link_click_policy">0</parameter>
<parameter name="redirect_limit">20</parameter>
<parameter name="save_html">false</parameter>
<parameter name="save_images">false</parameter>
<parameter name="save_objects">true</parameter>
<parameter name="save_multimedia">false</parameter>
<parameter name="save_others">false</parameter>
<output process="report"/>
</service>
<service name="reporter" id="reporter0">
<parameter name="serviceName">webclient</parameter>
<parameter name="template">webclient.jsont</parameter>
</service>
<!-- determine classification, taking into account propagation from child objects -->
<script>!findByValue("parent", #current).
{? #this.origin != "link" and #this.classification == "malicious"}.isEmpty
or rb_officecat_classification == "malicious"
? (classification = "malicious") :
(classification = "benign")</script>
<service name="reporter" id="reporter1">
<parameter name="serviceName"/>
<parameter name="template">url.jsont</parameter>
</service>
</process>
<process id="report">
<service name="reporter" id="reporter4">
<parameter name="serviceName">webclient</parameter>
<parameter name="template">webclient.jsont</parameter>
</service>
<service name="reporter" id="reporter5">
<parameter name="serviceName">file</parameter>
<parameter name="template">file.jsont</parameter>
</service>
<conditional expr="content != null and (mime_type == 'application/msword' or
mime_type == 'application/vnd.ms-excel' or mime_type ==
'application/vnd.ms-powerpoint')">
<true>
<service name="rb-officecat" id="office1"/>
<service name="reporter" id="reporter6" ignore_errors="INPUT">
<parameter name="serviceName">rb-officecat</parameter>
<parameter name="template">rb-officecat.jsont</parameter>
</service>
</true>
</conditional>
<!-- determine classification, taking into account propagation from child objects -->
<script>!findByValue("parent", #current).
{? #this.origin != "link" and #this.classification == "malicious"}.isEmpty
or rb_officecat_classification == "malicious"
? (classification = "malicious") :
(classification = "benign")</script>
<service name="reporter" id="reporter7">
<parameter name="serviceName"/>
<parameter name="template">url.jsont</parameter>
</service>
</process>
</workflow>
This workflow example should be interpreted as follows: we define a main process that uses the service “feeder-list“. It reads the links to be analyzed from a file located in /tmp/file.txt. The links are passed to the process_url process. This process uses the service “webclient” to visit those links, getting as a parameter some actions it should do or not to do, such as saving multimedia objects, and so on. The links collected for this service will be passed to the report process.
Besides webclient, the process process_url has several services that generate output information for the web interface. Finally, the report process is where the service that scans the Office files with the razorback nugget, “rb-officecat” is located, besides printing information using the service report. We want to emphasize the importance to set which content must activate the service. In this case it has been limited to start running only with contents that apply.
After loading the workflow in our tool, we input it with a file with links. In our scenario we have included a link to a malicious office document, resulting in:

If we click on the detected document we will see the vulnerability detected by rb-officecat:
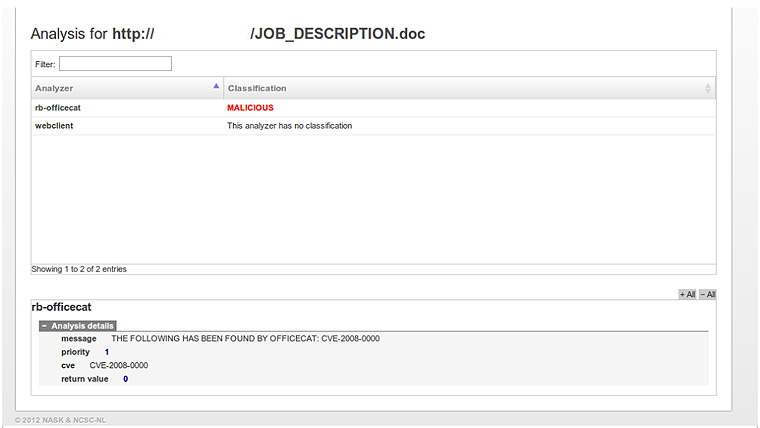
This is just one example of the detection abilities of this tool. As seen, the definition is simple and as we discussed in the previous post (ES) it has great possibilities. At this moment it is in an early stage and certain aspects will require fighting to get them to work as we want, but you can also report the problems in the Google group of the tool.