
Durante la gestión de casos forenses, hay veces que nos encontramos en un callejón sin salida, donde tras la detección de un indicador de compromiso de carácter crítico, nos toca abordar un análisis con evidencias poco sólidas.
Es por ello, que decidí llevar a cabo el desarrollo de una herramienta de carving que se basara en la detección con reglas Yara. Dicha herramienta también debía de manejar archivos en raw y ser capaz de llevar a cabo una gran variedad de opciones sobre estos datos de manera flexible, por lo que decidí utilizar Radare2.
De esta combinación nació YaraRET, una herramienta de carving de ficheros desarrollada en Go, cuya versión estable está disponible en el repositorio de YaraRules: https://github.com/Yara-Rules/YaraRET
La versión de desarrollo puede ser encontrada en el siguiente repositorio: https://github.com/wolfvan/YaraRET
Así pues, durante el siguiente artículo se va a exponer la resolución de un caso forense ficticio con YaraRET, el cual está basado en la combinación de varios casos que me he ido encontrando desde hace unos cuantos meses.
El caso
Imaginemos que se nos remite un equipo que, según nos informan, ha realizado una petición contra un dominio de APT33. La gestión del incidente parece no haber sido la más idónea, por lo que no puede descartarse que un posible atacante haya borrado sus huellas.
En cuanto al equipo, se trata de un sistema industrial que utiliza una versión de Windows XP para dispositivos embebidos, el cual trata información muy sensible y, es por esto mismo, por lo que el cliente nos solicita que extraigamos la mayor cantidad de información sobre el posible malware existente en el equipo, de cara a poder llevar a cabo una fase de erradicación total de la amenaza.
Tras un primer vistazo, encontramos un malware, el cual es de carácter genérico y no parece estar relacionado con la petición objeto del análisis forense. Los logs de la máquina han rotado y no tenemos pistas sólidas a las que agarrarnos.
Dado que en el repositorio de Yara Rules existe una gran variedad de firmas, desesperado, decido lanzar el set de reglas de APT33 contra todo el raw del disco.
Encontramos un match.
Breve inciso:
En el momento de la redacción del caso y su presentación en la r2con2018, la hipótesis principal era que el actor detrás de TRISIS era APT33. Ahora, en el momento de la redacción del artículo, nuevas fuentes apuntan a que pudiera haber sido APT28. Para mostraros YaraRET y su funcionamiento, es indiferente que haya sido uno u otro. Además, seguro que ha sido USA ;P
La herramienta
En este punto decido crear una herramienta muy sencilla que, utilizando los match reglas de malware de Yara y, utilizando otro set de reglas de magic numbers creadas ad hoc, lleve a cabo la detección y extracción de ficheros.
Así pues, al ejecutar la herramienta, ésta llevara a cabo la ejecución del ruleset de Yara indicado, y en caso de encontrar algún resultado, ejecutará el ruleset de magic numbers integrado en la herramienta, definiendo estructuras de datos, para, posteriormente dumpear el archivo.
Para optimizar la ejecución de la herramienta, se ha definido un intervalo de búsqueda de magic numbers, por lo que se incluye el parámetro de tamaño máximo.
El resultado es el siguiente:
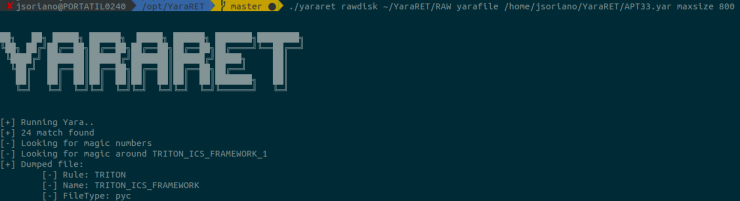
Perfecto, hemos obtenido un fichero de tipo pyc, el cual, efectivamente, es malware asociado a APT33.
Sin embargo, tras indagar en su análisis, únicamente obtenemos que se trata de un módulo del malware.
Otro dato que podemos utilizar son los diferentes indicadores de compromiso que existen sobre TRISIS. Para ello, YaraRET incorpora la posibilidad de parsear direcciones IP y dominios para crear reglas Yara que posteriormente ejecutará contra el raw, del mismo modo que en el caso anterior.
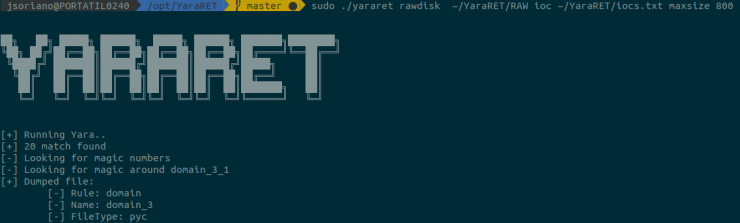
De nuevo, únicamente hemos obtenido un resultado, y se trata del mismo archivo detectado con anterioridad.
Utilizando esta pista, podríamos tirar del hilo en una investigación con otras herramientas forenses más “al uso”. Sin embargo, el software de comunicación del sistema industrial está basado en librerías pyc, por lo que el número de archivos pyc se cuentan por centenares.
Era necesario que descartara, de algún modo, aquellos archivos legítimos, cosa que suponía llevar a cabo, no sólo la extracción “tonta” de ficheros, si no aplicar una correlación.
Hasta este punto, la prioridad de la herramienta era ser rápida, sin embargo, dado que era necesario mejorar la herramienta, decidí apostar por perder algo de tiempo en el inicio del análisis, de cara a definir las estructuras de todos los ficheros deseados y poder llevar acciones en dichas estructuras.
Es por ello que decidí desarrollar un modo shell.
Cosa que veremos en el próximo capítulo ;)