
=> I: acquisition and processing
=> II: simple analysis
=> III: not so simple analysis
=> IV: conclusions
Once we have processed the gathered information we can start our analysis trying to ask the silly and simple questions that many times we wonder. Let’s go.
Which are the groups with more synonyms?
The silliest question I always wonder is why we use so many names for the same actor. Which one is the group with more names? Let’s see:
$ for i in [0-9]*.txt; do c=`grep synonyms\", $i|grep -vi operation|wc -l `; echo $c $i;done |sort -n|tail -1
18 233.txt
$
The result is “233.txt”, which corresponds to APT 28, with 18 synonyms; the second one in the ranking, with 16 names, is Turla. Casually, both of them are from Russia (we’ll see later some curiosities about Russia).
Apart from that, a personal opinion: 18 names for the same group! Definitely, once again, we need a standard for threat actor names. This can be your first sentence when giving a talk about APT: where is an ISO committee when it’s needed?
Which groups are from my country?
Well, outside well known actors… how many groups are from my country? Spanish ISO 3166-1 country code is ES, so let’s look for Spanish threat actors with a simple command, as well as threat actors from other relevant countries
$ grep \"country\" [0-9]*.txt|grep -w ES
$ grep \"country\" [0-9]*.txt|grep -w DE
$ grep \"country\" *.txt|grep -w IL
183.txt:["values",183,"meta","country"] “US,IL"
$
No identified groups from Spain… well, I’m sure this has a technical explanation: Spanish groups are so stealth that they are difficult to discover, and their OPSEC is so strong that, in case of being discovered, attribution is impossible. For sure! But what about Germany? Where is your Project Rahab now? And what about Israel, with only a sad starring together with US? Yes, it’s Stuxnet, but only a single starring… I hope you are as good as Spanish groups: nobody can discover you, and attribution is impossible :) Another sentence for your APT talks: in the group of most stealth countries we can find Germany, Israel… or Spain.
Has any threat group a clear attribution?
The answer, exploiting our data, is simple: NO. All groups have a “50” attribution confidence.
$ grep attribution-confidence [0-9]*.txt|awk '{print $2}'|grep -v ^\”50\"
$
One moment… this is an error. How can FBI show folks from Russia, China or Iran in their “most wanted posters” without a clear attribution? Attribution matters, and I personally think some groups (just like APT28, my favorite one) should have a higher attribution confidence value.
Which are the most targeted countries? And the most targeted sectors?
Once we have answered our silliest questions, it’s time to wonder just simple ones… in this first case, no analysis has to be performed, as ThaiCERT directly shows these statistics in their portal. The most targeted country is US, followed by UK. Who could imagine that? :) And the most targeted sectors are Government and Defense. Also a big surprise…
Which are the most active countries?
As before, no analysis has to be performed. No surprises here: China, Russia and Iran are the most active countries, in this order, followed by North Korea.
Which is the most analyzed threat group?
A simple query gives you the answer:
$ for i in [0-9]*.txt; do c=`grep refs\", $i|wc -l `; echo $c $i;done |sort -n|tail -1
69 233.txt
$
The result is “233.txt”, which corresponds to APT28, with 69 references in the database (remember, APT28 was also the group with more synonyms…both facts are obviously related); the second one in the ranking, with 58 references, is Lazarus.
Which are the oldest threat groups? How is the distribution of threat groups discovery/activity among time?
This is a more interesting question than previous ones… Let’s construct and print a simple associative array from our data:
$ grep \"meta\",\"date\"\] [0-9]*.txt|awk '{print $2}'|sed 's/\"//g'|awk '{a[$0]++}END{for(k in a){print k,a[k]}}' >years
$
Now we plot the file to see results:
gnuplot> set boxwidth 0.5
gnuplot> plot 'years' with boxes
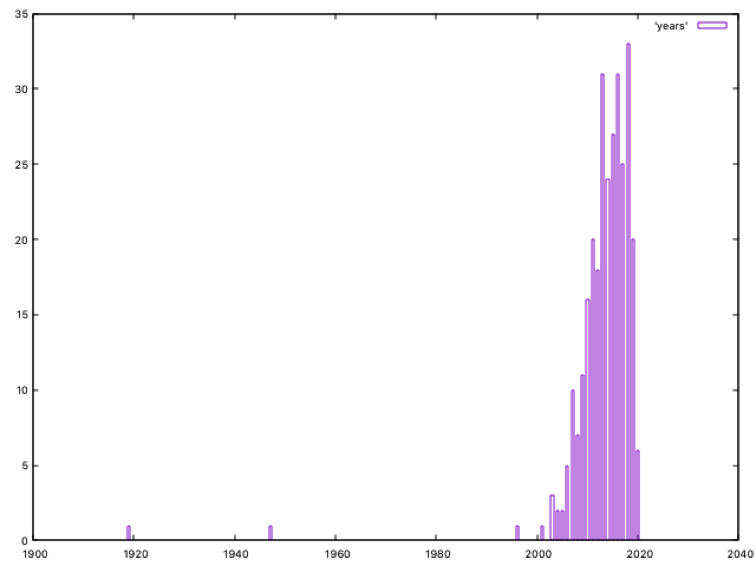
We can see two clear outliers, one dated at 1919 and the other dated at 1947; the first one is UK GCHQ and the second one is US CIA, and they both show the date when those services were established. As no other group is considered in this way (for example, Sofacy/APT28 “date” is not set to 1942, the GRU one), we could adjust those dates to a more realistic ones; but as this is not a IEEE paper about anomaly detection, but a simple blog post, it’s faster to simply remove both txt files and re-run to get our results (and set xtics to 1 in gnuplot):
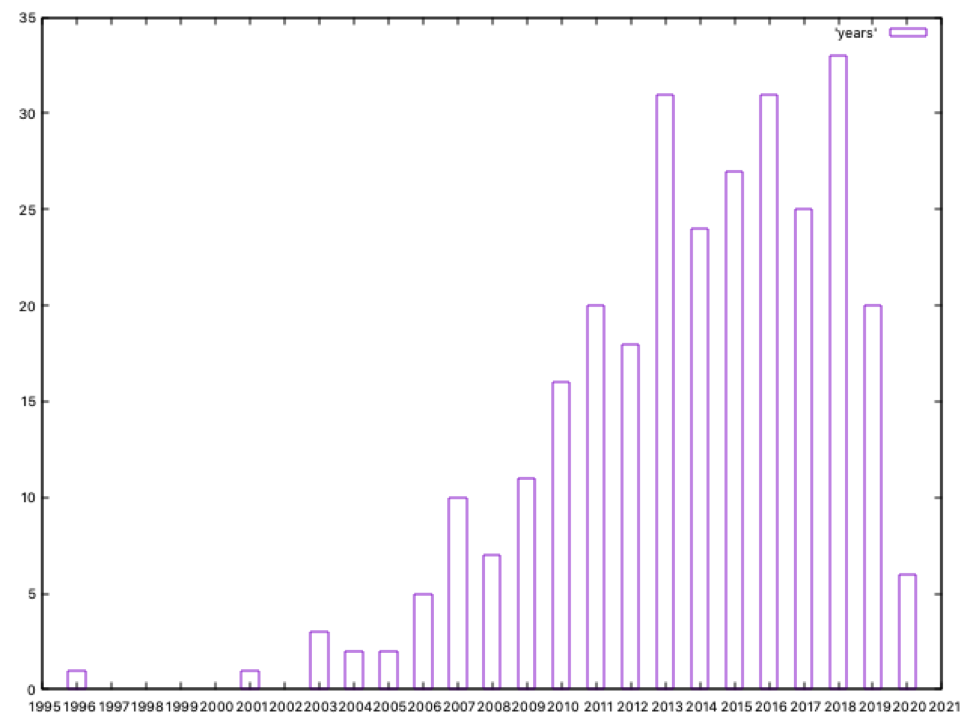
We can see the oldest APT group is dated on 1996; looking at our txt files, this group is Turla, which started its activities 24 years ago. Five years later, in 2001, Equation Group officially started to operate (but we all suspect this is not probably true, and they started before)
The number of identified groups operating since 2010 is growing fast; 2018 is the year when most groups are dated, a total of 33.
Which are the main motivations for APT groups?
Again, associative arrays are our friends:
$ grep \"motivation\", [0-9]*.txt |awk -F\" '{print $8}'|sed 's/\"//g'|awk '{a[$0]++}END{for(k in a){print k,a[k]}}'
Financial gain 32
Information theft and espionage 216
Sabotage and destruction 14
Financial crime 50
$
No hacktivism, no surprise… As we suspected, most threat groups are focused on CNE operations, more than on CNA ones… We’ll focus later on the last threat groups, those with destructive or manipulation capabilities…