
By José González (@bitsniper) en colaboración con Damià Poquet (@DamiaPoquet)
Introducción
Como los lectores ya se habrán percatado, “Pokémon Go” está en boca de todos, o más bien en “mano” de todos –incluso este blog tiene ya alguna entrada sobre esto–. Para el lector más despistado, Pokémon Go es un juego de realidad aumentada de la famosa empresa Nintendo en colaboración con Niantic –empresa que algunos podrán recordar del juego similar Ingress–. La finalidad de este juego es la de recorrer diversos emplazamientos físicos en busca de unas criaturitas llamadas “Pokemon”, al igual que en los demás juegos de la misma franquicia.
¿Qué tiene de especial? Pues bien, este juego ha enganchado especialmente a la generación del 80/90 que creció con estos juegos, mezcla de nostalgia y con afán de alimentar al “friki” que llevamos dentro, además de un –como llaman hoy en día– hype descomunal.
Actualmente se encuentra según sus creadores en fase Beta, a pesar de ser una versión “1.0.1” –al momento de escribir este artículo–, sí, yo también opino que deberían leerse el estándar de semver, el hecho de estar en Beta significa que este juego tiene muy pocas de las features prometidas, y una cantidad equiparable a su hype de fallos, de todo tipo, en especial de su infraestructura –servidores caídos–, y cuando llevas unos cuantos kilómetros recorridos, es decir, unas cuantas horas de juego te das cuenta que existen patrones… ¿mentalidad de “segurata”?
Mecánica de juego
La mecánica básica del juego es simple, un “Entrenador Pokémon” (el jugador), recorre las calles en busca de Pokemons, de los cuales existen 150, fácil, ¿no? Pues no, ya que estos aparecen “aleatoriamente” por todo mapa, es decir, que la captura de un Pokemon es un hecho ligado al azar, con unas limitaciones, algunos son exclusivos de zonas determinadas, otros se “liberarán” en eventos concretos y los restantes están sujetos a unos ratios de spawn –aparición–.
Si esto nos parece sencillo, además, se añade que cada Pokemon tiene diversas estadísticas, ratio de probabilidad de captura, fuerza, salud ¡e incluso estadísticas ocultas! como aguante, ataque, defensa, etc. lo que hace que cuando encontremos el ansiado Pokemon, se nos pueda escapar o no tenga los atributos que queremos.
Ya no parece tan sencillo, ¿verdad? Pues vamos a ver que obtenemos si le damos unas cuantas vueltas de tuerca al juego :)
Gimme some data!
Como indica el título de este artículo, las siguientes líneas no tratan de seguridad en su vertiente más pura, si no de ¡analizar datos!, que en este caso no son muchos (sí, BigData queda bonito, así que lo utilizo como gancho).
¿De qué disponemos?
La comunidad de Pokemon es muy activa, siempre lo ha sido, y hay verdadero potencial entre las filas de fans, así que al poco de lanzarse el juego, se descodificó el protocolo de serialización de datos en formato protobuf (diseñado y utilizado por google), y poco después se creó una librería en python para hacer uso de la API de Pokémon Go.
¿Qué tenemos a nuestro alrededor?
Durante el juego, dispondremos en todo momento de un visor de Pokemons cercanos junto a un indicador de proximidad –actualmente ¿“roto”? o desactivado–, estos datos son mandados por el servidor del juego hacia nuestro dispositivo con los siguientes datos:
message MapPokemonProto {
required string SpawnpointId = 1;
required uint64 EncounterId = 2;
required int32 PokedexTypeId = 3;
required int64 ExpirationTimeMs = 4;
required double Latitude = 5;
required double Longitude = 6;
}
Esto es la definición de protobuf de un Pokemon cercano, es fácilmente entendible, –para el que quiera entender más a fondo como funciona protobuf, cosa que recomiendo, puede visitar su documentación–. En esta se aprecian datos interesantes, como Latitude, Longitude, PokedexTypeId y ExpirationTimeMs, los cuales nos indicarán las coordenadas en las que se encuentra el Pokemon, el tipo de Pokemon en cuestión y el tiempo de expiración del mismo, es decir, los Pokemon que encontremos no estarán siempre ahí hasta que los encontremos, además un elemento bastante interesante también, el SpawnpointId, ¿significa este parámetro que no spawnean Pokemons en localizaciones aleatorias?. Como último dato nos encontramos EncounterId, este es un ID generado aleatoriamente que indica el “spawn”, es el encargado de evitar que podamos obtener varias veces el mismo Pokemon mientras esté vigente (no haya expirado).
Con estos datos, el lector ya se habrá percatado del potencial de aplicar técnicas de análisis de datos sobre un set lo suficientemente grande :)
Obteniendo nuestros datos
Con la API y otras aplicaciones como “PokemonGo Map” podremos ver la localización de estos tan codiciados pedacitos de datos y TTL (Time To Live) restante, pero a un alto precio, la cuenta que utilicemos para esto probablemente acabe baneada tarde o temprano, y lo que es peor, Niantic pondrá cada vez más medidas de seguridad para evitar que la comunidad haga uso de este tipo de herramientas, así que queda bajo la responsabilidad del lector hacer uso de este tipo de aplicaciones.
Para obtener un set de datos lo suficientemente grande, utilicé la aplicación anteriormente mencionada (PGM) utilizando como fuente de recogida de datos el endpoint que pone a nuestro servicio PGM bajo la URL “hxxp://127.0.0.1:8000/raw_data”. Este nos devolverá un JSON con la siguiente estructura:
{
"gyms": […]
"pokemons": [
{
"disappear_time": 1469274025316,
"encounter_id": "NTMwNDQwNDE4MTEzNTExMjQ0NQ==",
"latitude": 39.45,
"longitude": -0.33,
"pokemon_id": 133,
"pokemon_name": "Eevee",
"spawnpoint_id": "0ffffffffff"
}
]
}
NOTA: El proyecto está bajo desarrollo activo, así que es posible que cuando el lector haga uso de esta, la estructura de datos haya sido modificada.
La obtención de estos se puede automatizar fácilmente con un pequeño script que descargue este JSON cada N minutos mediante una curl guarra y simplemente con:
while true; do printf "Downloading… "; \ curl --silent -k 'http://127.0.0.1:8000/raw_data' \ -o pokes_$(date +%s).json;\ printf "Done…\n"; sleep 180; done
Para obtener una cantidad decente de datos deberemos dejar esto corriendo un par de días. Tras esto tendremos múltiples ficheros con, en la mayoría de casos, datos repetidos debido al solapamiento, ya que no todos los Pokemon tienen el mismo TTL.
Modelando nuestros datos
Para extraer los datos que necesito utilizo MongoDB, esta base de datos no relacional es extremadamente rápida y dispone de un framework de herramientas muy útiles para el análisis de datos como “MapReduce” y el “Aggregation Pipeline”.
Almacenado de datos
Antes de jugar con estas herramientas deberemos añadir nuestros datos a MongoDB, yo utilizo para ello Go con el driver “mgo”.
Para añadir los registros únicos y evitar datos duplicados, deberemos aprovechar el campo EncounterId de nuestros datos, ya que como mencionamos anteriormente cada “spawn” dispone de este ID de forma única.
A los números gruesos
Una vez cargados nuestros datos en MongoDB, vamos a obtener los números gordos para tener una visión global de lo que podemos obtener:
En mi caso la zona de muestreo corresponde a las inmediaciones del cuartel general de los entrenadores Pokemon de SecurityArtWork, en la imagen se muestra el cuadrante muestreado:
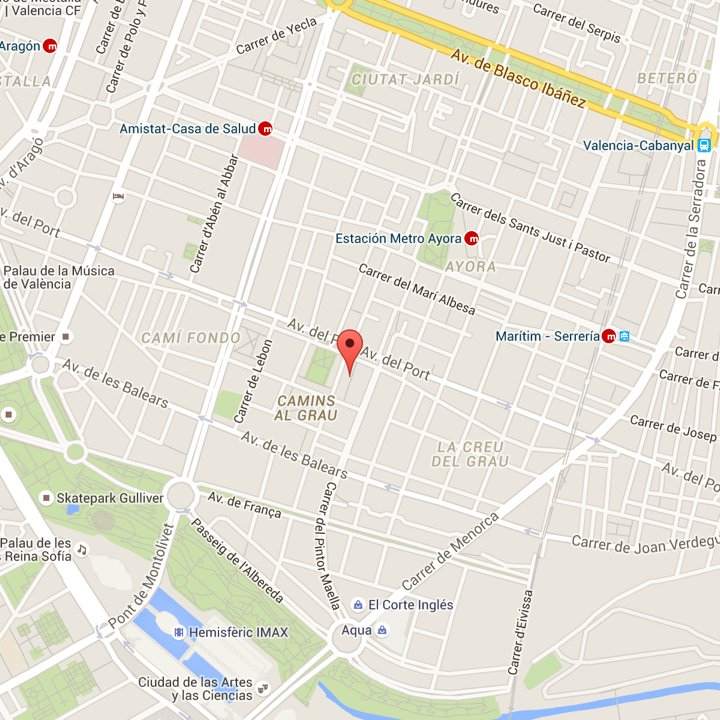
En este caso los datos recogidos durante 3 dias son los siguientes:
- Total de “spawns” únicos (encounter_id): 38627
- Spawn points únicos (spawnpoint_id): 558
- Inserciones por hora (x̄): 558
- Diferentes tipos de Pokemon (pokemon_id): 110
- Media de tipos de Pokemon asociados a un spawn: 15
- Los 10 Pokemon menos “spawneados”:
- Golduck: 1
- Omastar: 1
- Weezing: 1
- Weepinbell: 1
- Poliwhirl: 1
- Charmeleon: 1
- Exeggutor: 1
- Gyarados: 1
- Haunter: 1
- Nidorino: 1
- Los 10 Pokemon más “Spawneados”:
- Pidgey: 6786
- Rattata: 6073
- Zubat: 6027
- Ekans: 3174
- Paras: 2480
- Meowth: 1670
- Growlithe: 1607
- Mankey: 1606
- Spearow: 1460
- Magmar: 607
Con estos datos en pantalla ya podemos ver algunas relaciones interesantes, como que el ratio de “spawn” medio es de 1 Pokemon/hora por spawn, y que si no recorremos otras zonas el máximo de Pokemon diferentes que podremos obtener será de ~110 tipos. También confirmamos lo que ya todos sabemos, que hay superpoblación de diversos tipos.
En cuanto a la hora de analizar los “spawns” rápidamente descubrimos ciertas anomalías:
0d60378c8bf: Bulbasaur: 21 Pidgey: 14 Rattata: 8 Paras: 3 Abra: 1 Ekans: 5 Doduo: 1 Meowth: 2 Zubat: 9 Pikachu: 1 Sandshrew: 1 Mankey: 1 Eevee: 1
Como se observa en el “spawn” 0d60378c8bf tenemos una anomalía estadística demasiado grande como para ser casualidad, en este caso tenemos elementos que representan el 17.5% del total de “spawns” superados por elementos que representan el 0.4% casi por un factor de 2, el “Bulbasaur”.
Este punto no es un caso aislado, encontramos este comportamiento en numerosos “spawns”:
0d60378d1bb: Spearow: 2 Mankey: 5 Lickitung: 24 Rattata: 5 Growlithe: 5 Pidgeotto: 2 Ekans: 6 Zubat: 11 Paras: 4 Pidgey: 7
Tras una pequeña búsqueda se observa que diversos “spawns” actúan siguiendo este patrón, es decir, tienen preferencia por generar un tipo en concreto de Pokemon, algunos ejemplos son los siguientes:
0d60378aba3: Exeggcute: 19 0d603781c2d: Dratini: 28 0d6037828cf: Tangela: 27 0d60378cf9d: Hitmonchan: 20 0d60378ca8f: Seel: 20 0d60378ac5f: Scyther: 20
El lector ya se habrá percatado que estamos ante “generadores” de Pokemon específicos. En estos puntos podremos obtener los Pokemons deseados en grandes cantidades con unas probabilidades muy altas.
Con esto, espero, que el usuario profano haya vislumbrado el potencial del análisis (muy básico en este caso) de grandes “sets” de datos. Pero… ¿Ya está? ¿Esto es todo? ¿Dónde están los gráficos? No, aún no hemos acabado, esta parte manual es muy bonita, rápida y simple y para nuestros fines casi es suficiente, pero ¿qué tal si le damos una vuelta más de tuerca y utilizamos un framework de análisis y visualización de datos?
Pasto para los Alces
Colaboración especial de Damià Poquet (@DamiaPoquet)
Una vez visto en detalle cómo se estructuran los datos y que es lo que podemos encontrar en ellos, vamos a hacer aquello que indica el título de este artículo. Let’s go Big Data!
Es el momento de recoger datos de toda la ciudad de Valencia utilizando el mismo mecanismo, pero esta vez haciendo uso de múltiples procesos, cada uno recogiendo datos de una zona distinta de la ciudad. Gracias a distribuir la carga podemos obtener datos en tiempo real, ya que de lo contrario al algoritmo de búsqueda no le sería posible recorrer toda la ciudad en el tiempo necesario para recoger todos los posibles “spawns”.
Con el fin de almacenar todos estos datos para su posterior análisis, utilizaremos el conocido framework “ELK Stack” compuesto por Logstash (para el parseo de los datos JSON que obtenemos), ElasticSearch (para guardar ordenadamente los datos), y Kibana (para la visualización de los resultados). La instalación de este framework es muy sencilla, únicamente tendremos que descargar los paquetes disponibles en sus repositorios oficiales e instalarlos. Sin embargo, conseguir parsear y guardar toda la información de forma correcta es un gran quebradero de cabeza.
El primer paso es configurar Logstash para que lea la información, la parsee y se la envíe a ElasticSearch. Para ello Logstash hace uso de plugins en función de la entrada de datos y se pueden moldear a gusto de uno. Esta es la configuración final con la que hemos recogido los datos:
input {
http_poller {
urls => {
pokemap => "http://localhost:5001/raw_data"
}
request_timeout => 10
interval => 15
codec => "json"
}
}
filter {
mutate {
rename => [ "latitude", "[location][lat]" ]
rename => [ "longitude", "[location][lon]" ]
}
mutate {
convert => { "[location][lat]" => "float" }
convert => { "[location][lon]" => "float" }
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
document_id => "%{encounter_id}"
document_type => "pokemon"
index => "pokemap"
}
}
A grandes rasgos, consiste en realizar un “pull” de los datos cada 15 segundos en busca de datos nuevos, convertir los puntos geográficos al formato que le gusta a ElasticSearch y enviárselo todo. Es importante realizar un mapeo de los datos identificativos para evitar que por defecto utilice su propio indicador de evento, generando así muchos datos duplicados. Recordemos que en nuestro caso el identificador es el campo “encounter_id”.
El siguiente paso es crear un índice en ElasticSearch con el nombre indicado anteriormente donde se guardarán los datos. Dispone de un motor muy potente capaz de detectar automáticamente el tipo de datos de entrada, a excepción, nuevamente, de los puntos geográficos, los cuales debemos indicar específicamente su tipo con el siguiente comando:
curl -XPUT 'http://localhost:9200/pokemap' -d '
{
"mappings": {
"pokemon": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
}'
De esta forma ya deberíamos estar viendo en Kibana como nuestros datos van entrando ordenadamente.
Ahora llega lo divertido, ¡el análisis! Kibana nos permite visualizar nuestros datos en forma de tablas, gráficas de barras, gráficas de línea, tartas, mapas… Todo ello de manera ágil y rápida si disponemos de buenos recursos en nuestra máquina.
Lo primero a comprobar es si los datos obtenidos anteriormente para una pequeña zona, se cumplen a gran escala. Estos son los números:
- Total de “spawns” únicos (encounterid): 196.854
- Spawn points únicos (spawnpointid): 4.427
- Inserciones por hora (x̄): 4.250
- Diferentes tipos de Pokemon (pokemonid): 136
- Media de tipos de Pokemon asociados a un spawn: 15
Con esto podemos confirmar que los datos para una zona pueden extrapolarse a grandes zonas, ya que la media de “spawn” por hora en cada lugar se mantiene a aproximadamente 1 Pokemon, y podemos encontrar una media de 15 Pokemon diferentes en cada lugar. También podemos observar como los tipos de Pokemon más y menos comunes se mantienen.
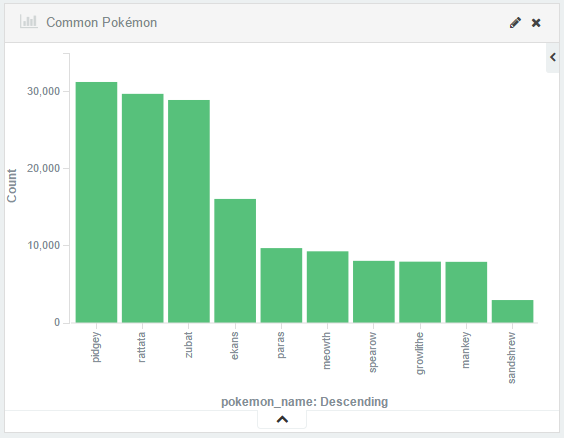
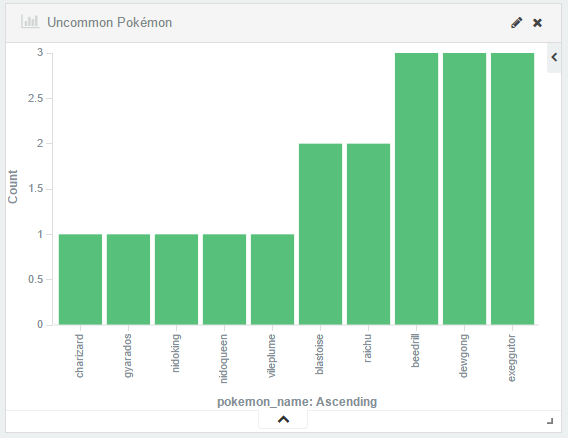
Es el momento de aportar datos nuevos, como puede ser la distribución de Pokemon por zonas. En este mapa observamos a grandes rasgos en que zonas de Valencia hay mayor acumulación de puntos de “spawn”:
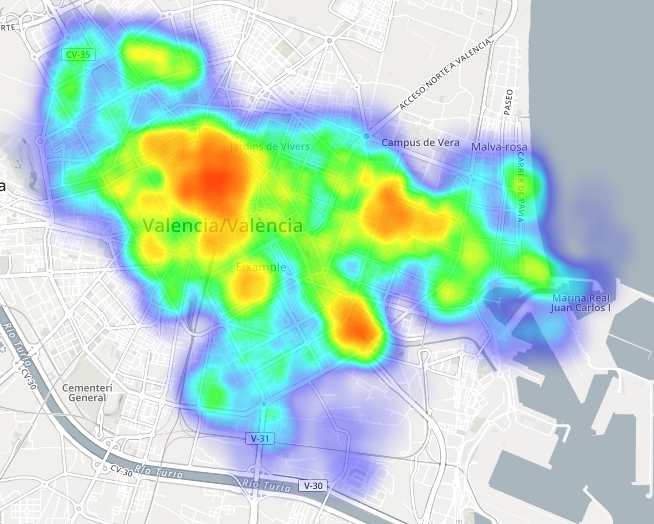
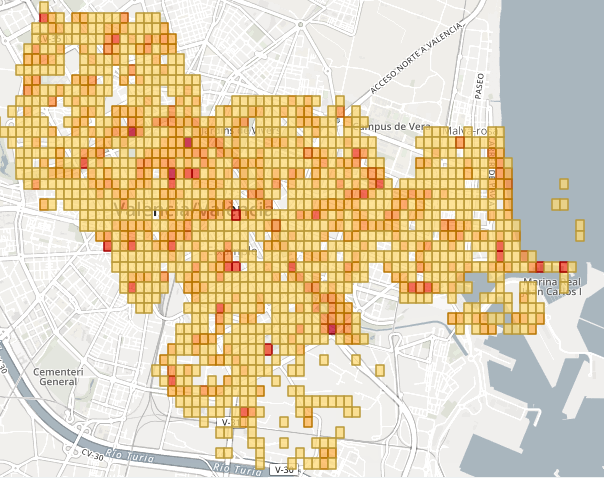
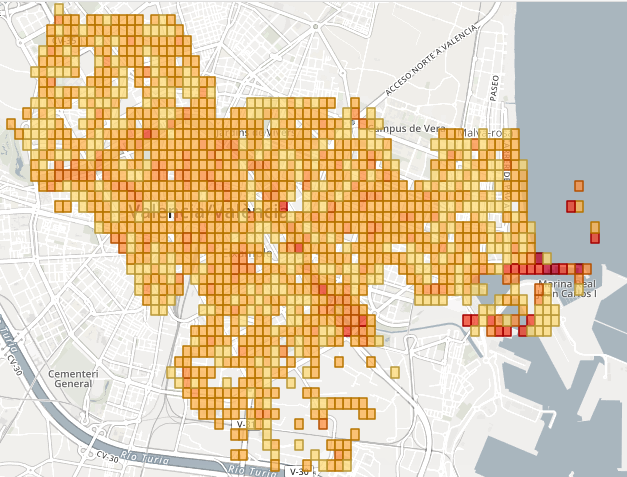
Con esto nos hacemos a la idea de por dónde debemos pasear si queremos muchos Pokemon, pero… ¿Y si además queremos variedad de Pokemon? La respuesta nos la dan estos dos mapas. En el primero observamos lo mismo que en anterior pero con mayor precisión al ver una rejilla de puntos pequeños, mientras que en el segundo lo que estamos observando es el número de tipos de Pokemon distintos que aparecen en cada punto de “spawn”. Si hacemos coincidir ambos mapas y buscamos el punto más oscuro encontraremos el mejor punto de la ciudad para capturar Pokemon, tanto por su número de apariciones como por variedad.
En Valencia el “punto estadísticamente perfecto” se encuentra en “El Espigón de la Marina Real Juan Carlos I”, como se muestra en la siguiente captura:
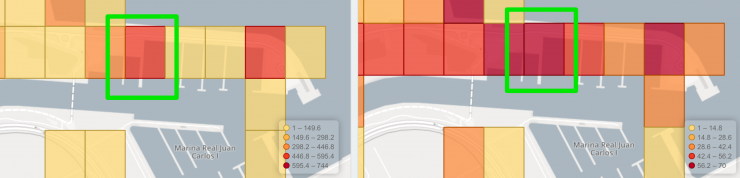
De la cual se debería proponer el cambio de nombre por “Marina Real del Entrenador Pokémon”.
Feed the ELK
Esperamos que este artículo le haya parecido interesante a los lectores, y haya despertado el gusanillo para iniciarse en el fascinante mundo de “las agujas en los pajares”.
En este caso hemos decidido utilizar Pokémon debido a su gran popularidad y “novedad”, pero otra gran fuente de datos es Twitter, y seguro que en cuanto jueguen un poco con los datos disponible descubrirán mil y una aplicaciones de las herramientas comentadas para extraer datos interesantes a la vez que útiles.
Feed the ELK and go supersized!
Muy buen post, pero me queda una duda. ¿Se podrian poner medidas de seguridad para no usar la API con el fin de conocer donde se encuentran los Pokemon? ¿O lo unico que pueden hacer es detectar las herramientas que hacen ese uso y bloquearlas?
Buenas Pedro,
La respuesta corta, no.
La respuesta larga, el cliente tiene que tener acceso a los datos que se envían, por lo que podrían añadir diversas capas de seguridad, pero al final el cliente está en manos del usuario y con más o menos trabajo siempre será posible acceder a estos datos.
Lo que si se podría hacer, e imagino que en un futuro se hará –actualmente ya tienen bastantes frentes abiertos con su infraestructura básica–, será detectar patrones que puedan indicar un uso automatizado, esto no es sencillo, aunque ya hay diversos proyectos que afrontan el problema con heurística y machine learning, esto nuevamente no sería definitivo, pero puede añadir un “quebradero de cabeza” más a los desarrolladores de las APIs.
Como con todo, no hay sistema seguro al 100%
Happy hunting!
A mí lo que se me ocurría era cifrar los datos o codificarlos de cierta manera que solo la aplicación fuera capaz de “entender” esos datos y así obtener la información necesaria. Pero no estoy seguro de si seria posible. Gracias por la repuesta y un saludo.
Buenas Pedro,
Sí, sería posible, pero como comentaba antes, recuerda que el cliente tiene que ser capaz de descifrar esos datos, solo sería cuestión de tiempo que alguien consiguiera obtener la clave de cifrado y el algoritmo de cifrado empleado.
Otra solución tal vez mucho menos descabellada y mucho más eficiente puede ser utilizar “API Rate Limits”, estableciéndolos a unos límites lo suficientemente altos de lo que sería un uso “humano” de ella y bloquear las peticiones en cuanto sobrepase este threshold. Nuevamente, solo harían falta múltiples cuentas e ir cambiando entre ellas.
Ya veremos lo que nos depara el futuro :)
Un saludo!
Muy interesante José :) No sabía que había un buen developer viviendo tan cerca de mi casa! Concretamente enfrente