
=> I: adquisición y procesamiento
=> II: análisis simple
=> III: análisis no tan simple
=> IV: conclusiones
Con la información ya procesada y lista podemos empezar el análisis por la parte mas sencilla: las preguntas tontas y las preguntas simples que en muchas ocasiones nos planteamos. Allá vamos.
¿Cuáles son los grupos con más sinónimos?
La pregunta más tonta que siempre me he planteado es por qué usamos tantos nombres diferentes para el mismo actor. ¿Quién tiene el privilegio de ser el grupo con más nombres? Veamos:
$ for i in [0-9]*.txt; do c=`grep synonyms\", $i|grep -vi operation|wc -l `; echo $c $i;done |sort -n|tail -1
18 233.txt
$
El resultado es “233.txt”, que corresponde a APT 28, con 18 sinónimos; el segundo clasificado, con 16 nombres diferentes, es Turla. Casualmente, ambos de Rusia (veremos luego algunas curiosidades de Rusia).
Aparte de esto, una opinión personal: ¡18 nombres para el mismo grupo! Definitivamente, y una vez más, necesitamos un estándar para los nombres de actores hostiles. Esta puede ser tu primera frase cuando des una charla de APT: donde está un comité ISO cuando se le necesita?
¿Qué grupos son de mi país?
Aparte de los actores que todos tenemos en mente (Rusia, China…), ¿tenemos grupos españoles? ¿Tenemos grupos de otros países relevantes? El código ISO 3166-1 para España es ES, por lo que podemos buscar actores españoles -y de otros países- con una orden simple:
$ grep \"country\" [0-9]*.txt|grep -w ES
$ grep \"country\" *.txt|grep -w DE
$ grep \"country\" *.txt|grep -w IL
183.txt:["values",183,"meta","country"] “US,IL"
$
Vaya, no hay grupos españoles. Por supuesto, esto tiene una explicación técnica sencilla: los actores españoles son tan discretos que son muy difíciles de descubrir, y su OPSEC es tan buena que, en caso de ser descubiertos, no es posible una atribución clara. Seguro, por supuesto… Pero, ¿qué hay de Alemania? ¿Dónde está ahora el proyecto Rahab? ¿Y qué hay de Israel, con una triste aparición junto a USA? Stuxnet, eso sí, pero solo una entrada… Seguro que son tan buenos como los españoles: nadie puede descubrirlos, y la atribución es imposible… Otra frase para las charlas: los países más discretos pueden ser Israel o Alemania, y por supuesto España :)
¿Algún grupo tiene atribución clara?
Explotando nuestros datos, la respuesta es clara: NO. Todos tienen un grado de confianza “50”.
$ grep attribution-confidence [0-9]*.txt|awk '{print $2}'|grep -v ^\”50\"
$
Pero un momento: esto debe ser un error. ¿Cómo si no el FBI cuelga en sus posters de los más buscados a gente de Rusia, China o Irán? La atribución importa, y (opinión personal) creo que algunos grupos como APT28 deberían tener un grado confianza en su atribución más alto.
¿Cuáles son los países más atacados? ¿Y los sectores más atacados?
Una vez hemos respondido a las preguntas tontas que nos planteábamos, vamos a por las sencillas, aunque no tan tontas… En este caso, no hay que hacer ningún análisis, ya que ThaiCERT directamente muestra estas estadísticas en su portal. El país más atacado es Estados Unidos, seguido por el Reino Unido… ¡quién lo habría imaginado! :) Además, los sectores más atacados son Gobierno y Defensa. De nuevo, ¡sorpresa!
¿Cuáles son los países más activos?
De nuevo, no es necesario hacer ningún análisis… y de nuevo sin sorpresas: China, Rusia e Irán son los países más hostiles, en este orden, seguidos por Corea del Norte.
¿Cuál es el actor más estudiado?
Una query simple nos da la respuesta:
$ for i in [0-9]*.txt; do c=`grep refs\", $i|wc -l `; echo $c $i;done |sort -n|tail -1
69 233.txt
$
El resultado es “233.txt”, que corresponde a APT28, con 69 referencias en la base de datos (recordemos que APT28 era también el grupo con más sinónimos… una cosa lleva a la otra); el segundo en el ranking, con 58 referencias, es Lazarus.
¿Cuáles son los actores más antiguos? ¿Cuál es la distribución del descubrimiento o actividades de los grupos en el tiempo?
Esta cuestión es al menos algo más interesante que las anteriores… Vamos a construir e imprimir un array asociativo con nuestros datos:
$ grep \"meta\",\"date\"\] [0-9]*.txt|awk '{print $2}'|sed 's/\"//g'|awk '{a[$0]++}END{for(k in a){print k,a[k]}}' >years
$
Ahora vamos a dibujarlo para ver los resultados:
gnuplot> set boxwidth 0.5
gnuplot> plot 'years' with boxes

Sin ser expertos, podemos ver dos grupos que se salen de lo normal, uno con fecha 1919 y otro con fecha 1947; el primero es el GCHQ británico y el segundo es la CIA estadounidense, y en ambos casos se muestra la fecha en que ambos servicios fueron fundados. Como ningún otro actor es considerado de esta forma (por ejemplo, la fecha de Sofacy/APT28 no está fijada a 1942, año de fundación del GRU ruso), podríamos ajustar estas fechas a alguna más real. Pero como esto no es un artículo de IEEE sobre detección de anomalías, sino un simple post en un blog, es más rápido borrar ambos archivos txt y ejecutar de nuevo para ver los resultados (y fijar xtics a 1 en gnuplot):
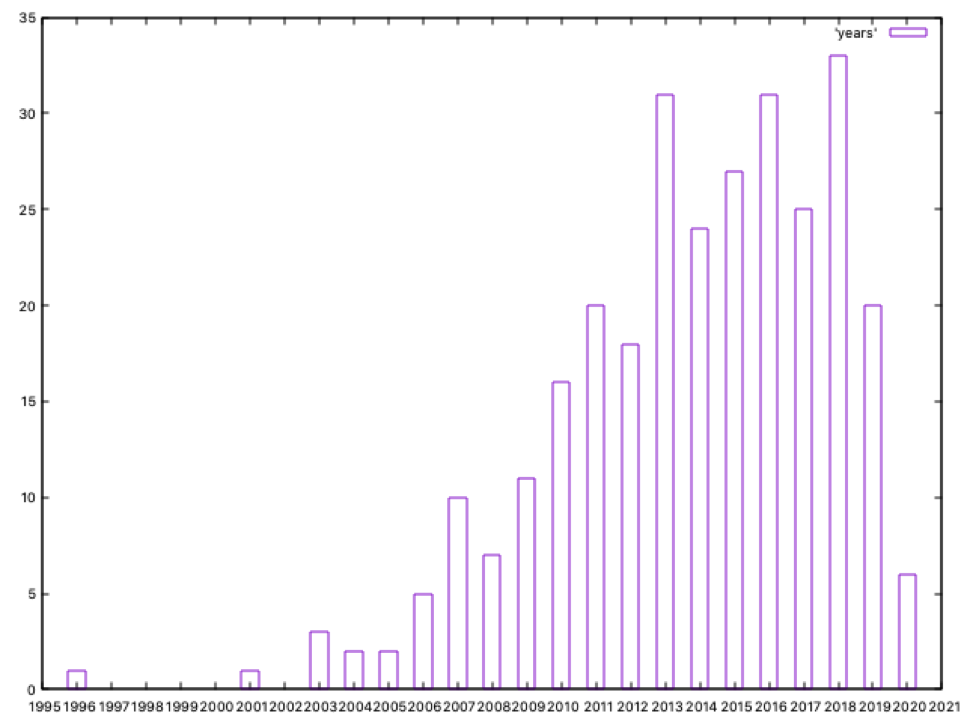
Ahora ya podemos ver que el grupo APT más antiguo está fechado en 1996; revisando los ficheros txt, este grupo es Turla, que arrancó sus actividades en 1996. Cinco años después, en 2001, Equation Group comenzó oficialmente a operar (aunque todos sospechamos que esto probablemente no es cierto y comenzaron antes).
El número de grupos identificados operando desde 2010 crece de forma rápida; 2018 es el año en el que más grupos arrancan sus actividades, un total de 33.
¿Cuáles son las principales motivaciones de los actores hostiles?
De nuevo, los arrays asociativos son nuestros amigos:
$ grep \"motivation\", [0-9]*.txt |awk -F\" '{print $8}'|sed 's/\"//g'|awk '{a[$0]++}END{for(k in a){print k,a[k]}}'
Financial gain 32
Information theft and espionage 216
Sabotage and destruction 14
Financial crime 50
$
Sin hacktivismo, sin sorpresas… Como sospechábamos, la mayor parte de actores se focalizan en operaciones CNE, mucho más que en operaciones CNA. Más tarde sacaremos algunas conclusiones de este último tipo de actores, los que disponen de capacidades destructivas o de manipulación.