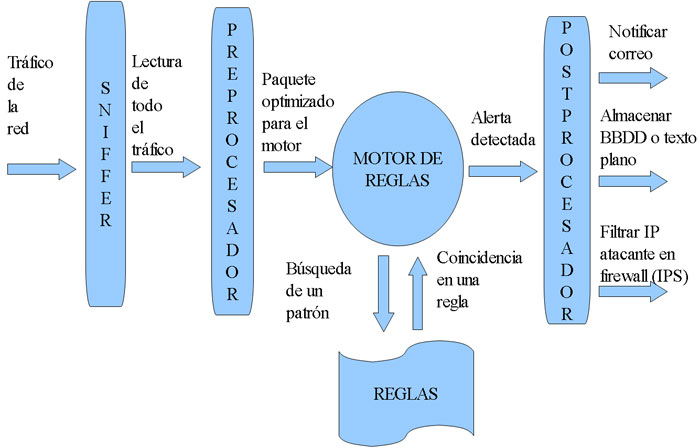
Tal como vimos en la anterior entrada, una forma sencilla de evadir el motor de reglas es emplear distintas codificaciones para intentar que el ataque no coincida con el patrón buscado por el IDS. Junto a lo visto con anterioridad, existen otros métodos sobre el protocolo TCP/IP para intentar evadir el motor de reglas. Veremos cuatro de los principales métodos de evasión a nivel de TDP/IP:
Explotar el tiempo de vida (TTL)
El TTL es un campo de las cabecera TCP/IP que se encarga de evitar que un paquete permanezca en la red para siempre. El TTL es un campo de 8 bits que indica el número máximo de enrutadores por los cuales puede pasar. Al llegar a un enrutador el TTL disminuye en 1, si el número resultante después de restarle 1 es igual a 0 el paquete es descartado, informando al emisor con un paquete ICMP de tipo Time Exceeded Message. A muchos de ustedes les sonará el campo porque es empleado por herramientas de tipo traceroute (véase esta entrada sobre las curiosidades del traceroute) para conocer los enrutadores por los que pasamos antes de llegar a nuestro destino.