(N.d.E. Para aquellos que no pueden vivir sin Internet durante las vacaciones —aquellos que las tengan—, aquí va una entrada sobre la securización de DMZ)
Generalmente, la arquitectura de seguridad de red en pequeñas empresas se basa en un elemento central de filtrado, habitualmente un firewall, y distintos segmentos de red conectados a él, principalmente, un segmento de red interna y un segmento DMZ para alojar servidores corporativos. En el caso de una empresa de tamaño medio o grande, la situación es bastante similar: uno o varios firewalls en alta disponibilidad separando distintos segmentos de red, aunque disponen de otros controles como NIDS, IPS, sistemas de monitorizacion, etc, y técnicos dedicados a la gestion de la seguridad.
Un problema habitual en este tipo de arquitecturas hace que siempre nos preguntemos: ¿que sucede si comprometen uno de mis servidores ubicados en la DMZ? Bien sea por un Zero-day, una mala configuracion del sistema, un exploit sin firma actualizada en nuestro IDS, etc., la respuesta suele ser siempre la misma: una vez comprometido un servidor del segmento, el atacante podria comprometernos el resto de los servidores puesto que la comunicacion entre los servidores ya no atraviesa el firewall central.
Para resolver este problema existen distintas soluciones, las cuales se basan entre otras en implantar HIDS o firewalls en los propios servidores, con el problema añadido de la complejidad de la gestion de la seguridad para los administradores o del consumo de recursos, aunque mínimo, de los sistemas implicados.
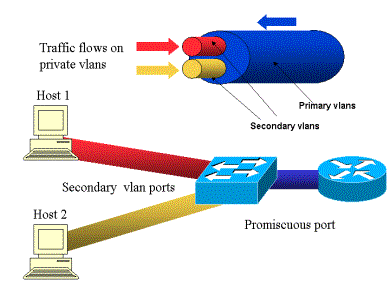 Un control de seguridad adicional para este tipo de situaciones es posible configurarlo a nivel de red, en concreto en los propios switches, y es lo que se conoce como Private Virtual Lan (PVLAN), una tecnologia (al parecer) ideada por Cisco Systems, aunque soportada por distintos fabricantes.
Un control de seguridad adicional para este tipo de situaciones es posible configurarlo a nivel de red, en concreto en los propios switches, y es lo que se conoce como Private Virtual Lan (PVLAN), una tecnologia (al parecer) ideada por Cisco Systems, aunque soportada por distintos fabricantes.
Habitualmente, una VLAN forma un unico dominio de broadcast donde todos los hosts conectados a ella pueden conectarse entre sí. Por el contrario, una Private VLAN permite una segmentacion en la capa 2 del modelo OSI, limitando el dominio de broadcast, de forma que es posible permitir conexiones de cada host con su gateway, denegando la comunicacion entre hosts, obteniendo el resultado deseado, de modo que si un host se ve comprometido, el resto de equipos podría mantenerse a salvo.
En arquitecturas basadas en PVLAN, cada puerto del switch puede configurarse de tres maneras distintas:
- Promiscuous: el puerto es capaz de enviar y recibir tráfico a cualquier puerto de la misma PVLAN.
- Community: el puerto puede enviar y recibir tráfico a un puerto configurado como promiscuo o a otros puertos de la misma comunidad.
- Isolated: el puerto solo puede enviar y recibir tráfico a un puerto configurado como promiscuo.
De esta forma, una PVLAN solo puede tener un puerto configurado como promiscuous (primary vlan) pero varios declarados como community o isolated (secondary vlan).
En la red DMZ que usamos como ejemplo, el puerto conectado al firewall seria declarado como promiscuous y los puertos que conectan los servidores serian declarados como isolated, siempre que no necesiten conectividad entre ellos, o community en caso de que la requieran. Por ejemplo, un servidor de aplicaciones que accede a un servidor de base de datos.
De esta forma, conseguiríamos un nivel de seguridad más para nuestras redes, en la línea de lo exigido por la ISO 27002 (A.10.6.1, Controles de red), y reduciendo los riesgos para un segmento especialmente expuesto a ataques y amenazas.
(Diagrama de Tech Republic. Pasen un buen y largo fin de semana y nos vemos el martes que viene, en el mismo sitio. Tengan cuidado con la carretera.)