
Comenzamos con este artículo una serie de tres entradas en las que se va a mostrar como construir un (relativamente) sencillo laboratorio virtual sobre una única máquina física para la detección y prevención de ataques. Como requisitos previos, el laboratorio se monta sobre un entorno Linux, empleando la herramienta VirtualBox para las máquinas virtuales. Para conectar las máquinas virtuales entre si se empleará un hub virtual mediante la herramienta de virtualización UML (uml_switch).
Este entorno va a estar formado por tres máquinas virtuales: la primera será la máquina atacante (Linux Debian), la máquina víctima (Windows 2000 SP4) y por último la máquina IDS (Linux Ubuntu Server). Esta última dispondrá de una serie de herramientas de monitorización para observar y analizar los ataques producidos desde la máquina atacante a la máquina víctima, y de esta forma localizar un patrón que identifique dichos ataques. En concreto hemos instalado un servidor OSSEC (HIDS), una sonda Snort sobre un MySQL con B.A.S.E. (NIDS) y un analizador de red (wireshark y tcpdump).
Hechas las pertinentes presentaciones, vamos al tajo. Primero de todo, comenzamos creando el hub virtual; en nuestro caso el usuario será jmoreno, el grupo jmoreno y la interfaz tap0:
# tunctl -u jmoreno -g jmoreno -t tap0 Set 'tap0' persistent and owned by uid 1002 gid 1002 # ifconfig tap0 10.0.0.4 netmask 255.255.255.0 up # uml_switch -hub -tap tap0 -unix /tmp/mipuente uml_switch will be a hub instead of a switch uml_switch attached to unix socket '/tmp/mipuente' tap device 'tap0' New connection (Veremos las conexiones a nuestro hub)
A continuación nos creamos tres máquinas virtuales con VirtualBox. La configuración de la red para cada máquina virtual será de “puente o bridge” seleccionando como interfaz “tap0”. Para nuestro laboratorio vamos a asignar las siguientes IPs a cada una de las máquinas virtuales:
Atacante: 10.0.0.1 Víctima: 10.0.0.2 IDS: 10.0.0.3
Para finalizar esta primera entrada, inicializamos las máquinas virtuales y comprobamos que la comunicación entre el servidor OSSEC y el cliente está funcionando correctamente. Adicionalmente realizamos una serie de calibraciones sobre el Snort que demuestran su correcto funcionamiento:
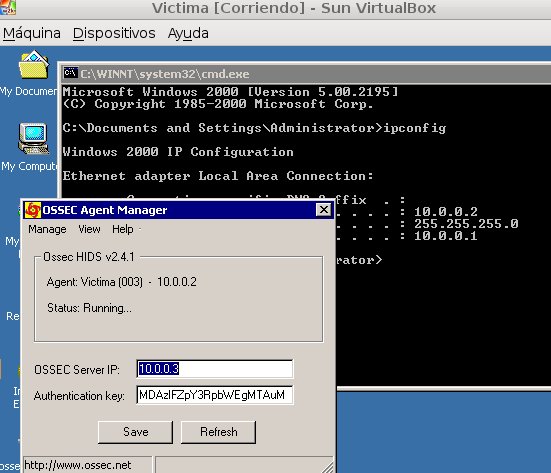
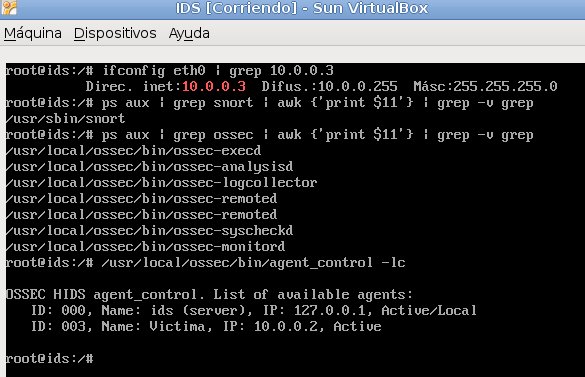
Como ven el funcionamiento es correcto. Por tanto en este momento disponemos de un laboratorio donde poder, desde la máquina atacante, explotar las vulnerabilidades de la Víctima, y a su vez, monitorizar mediante el IDS todos los sucesos que ocurren entre ambas máquinas, y encontrar patrones que permitan poder detectar dichos ataques. Por hoy, esto es todo; mañana continuaremos, aunque les recomiendo que, si están interesados y disponen de tiempo, ganas y un Linux para trastear, me acompañen durante estas entradas, e iremos resolviendo los problemas y dudas que les vayan surgiendo.
 Ayer, leyendo noticias sobre la serie “Lost”, de la cual soy fan, he visto algo que me ha llamado la atención. Panda Security, a través de
Ayer, leyendo noticias sobre la serie “Lost”, de la cual soy fan, he visto algo que me ha llamado la atención. Panda Security, a través de 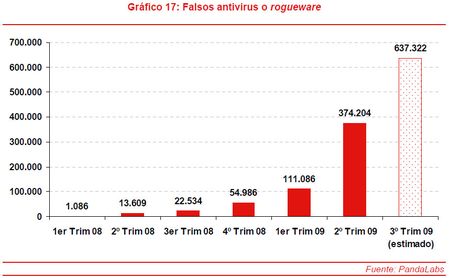 Los ‘rogueware‘ o falsos antivirus son un tipo de amenaza que consiste en falsas soluciones de antivirus diseñadas para obtener dinero de los usuarios, cobrándoles por “desinfectar” sus ordenadores de amenazas que, en realidad, no existen. Como se indica en la imagen de PandaLabs, las cifras indican que a mediados del 2009 se habían detectado cerca de 640.000 tipos diferentes de falsos antivirus, 10 veces mas que el año anterior. Como vemos este tipo de malware crece de manera espectacular, y se calcula que se infectan aproximadamente unos 25 millones de nuevos ordenadores cada mes, generando unos 34 millones de dólares mensuales. Por supuesto el tema económico es la razón mas importante por la que el crecimiento del malware no cesa. No me extrañaría nada que involucrada en el tema estuviese la Iniciativa Dharma.
Los ‘rogueware‘ o falsos antivirus son un tipo de amenaza que consiste en falsas soluciones de antivirus diseñadas para obtener dinero de los usuarios, cobrándoles por “desinfectar” sus ordenadores de amenazas que, en realidad, no existen. Como se indica en la imagen de PandaLabs, las cifras indican que a mediados del 2009 se habían detectado cerca de 640.000 tipos diferentes de falsos antivirus, 10 veces mas que el año anterior. Como vemos este tipo de malware crece de manera espectacular, y se calcula que se infectan aproximadamente unos 25 millones de nuevos ordenadores cada mes, generando unos 34 millones de dólares mensuales. Por supuesto el tema económico es la razón mas importante por la que el crecimiento del malware no cesa. No me extrañaría nada que involucrada en el tema estuviese la Iniciativa Dharma. Seguimos con
Seguimos con  Resulta que el pasado 27 de abril la agencia de protección de datos alemana realizó una queja a Google relacionada con la información Wi-Fi recogida por la flota de coches Street View, que por si no lo sabían, además de realizar fotografías, también capta información de SSIDs y MACs. El departamento legal de Google respondió que la única información Wi-Fi que recopilaban era, en efecto, esa. Es decir, en palabras de Google, que
Resulta que el pasado 27 de abril la agencia de protección de datos alemana realizó una queja a Google relacionada con la información Wi-Fi recogida por la flota de coches Street View, que por si no lo sabían, además de realizar fotografías, también capta información de SSIDs y MACs. El departamento legal de Google respondió que la única información Wi-Fi que recopilaban era, en efecto, esa. Es decir, en palabras de Google, que  Podemos empezar con nuestros “vecinos” los japoneses, que como saben en esto de las tecnologías de película siempre están al pie del cañón. Al parecer, existen ya tiendas de ropa en las que todas las prendas están etiquetadas con tags RFID pasivos, a partir de los cuales la infinidad de aplicaciones que pueden desarrollar es casi infinita. Una de éstas es la instalación de probadores con monitores en los espejos y antenas que interactuan con la ropa, de manera que al detectar la prenda podemos ver en la pantalla una imagen de la misma con toda la gama de colores posibles, todos los accesorios a juego con dicha prenda o incluso el mismo catálogo de la tienda. De esta manera, el cliente desde el mismo probador puede seleccionar lo que quiere probarse y qué tallas, mientras los vendedores, que monitorizan toda la información, les hacen llegar al probador las prendas solicitadas. De esta forma, con llevar una sola prenda al probador se puede salir de él con toda la temporada primavera-verano. Hasta el momento, los resultados han sido satisfactorios, ya que se ha conseguido aumentar la cesta media del cliente y destacarse frente a la competencia. Por supuesto, esto impone requisitos en cuanto al personal disponible para la atención de los probadores, y sería interesante ver esta tecnología en acción en una tienda estilo Bershka un sábado por la tarde.
Podemos empezar con nuestros “vecinos” los japoneses, que como saben en esto de las tecnologías de película siempre están al pie del cañón. Al parecer, existen ya tiendas de ropa en las que todas las prendas están etiquetadas con tags RFID pasivos, a partir de los cuales la infinidad de aplicaciones que pueden desarrollar es casi infinita. Una de éstas es la instalación de probadores con monitores en los espejos y antenas que interactuan con la ropa, de manera que al detectar la prenda podemos ver en la pantalla una imagen de la misma con toda la gama de colores posibles, todos los accesorios a juego con dicha prenda o incluso el mismo catálogo de la tienda. De esta manera, el cliente desde el mismo probador puede seleccionar lo que quiere probarse y qué tallas, mientras los vendedores, que monitorizan toda la información, les hacen llegar al probador las prendas solicitadas. De esta forma, con llevar una sola prenda al probador se puede salir de él con toda la temporada primavera-verano. Hasta el momento, los resultados han sido satisfactorios, ya que se ha conseguido aumentar la cesta media del cliente y destacarse frente a la competencia. Por supuesto, esto impone requisitos en cuanto al personal disponible para la atención de los probadores, y sería interesante ver esta tecnología en acción en una tienda estilo Bershka un sábado por la tarde. Aunque parezcan situaciones a décadas vista, lo cierto es que cada vez son funcionalidades que empezamos a asumir como posibles. Actualmente ya están desarrollando carros de plástico que no interfieran con las señales de radiofrecuencia, y muchas compañías están insertando etiquetas en los productos, primero a nivel de palets para disponer de la trazabilidad del producto en su recorrido logístico, pero en breve comenzarán a nivel de unidades, de manera que en los centros comerciales se puedan aprovechar de este potencial.
Aunque parezcan situaciones a décadas vista, lo cierto es que cada vez son funcionalidades que empezamos a asumir como posibles. Actualmente ya están desarrollando carros de plástico que no interfieran con las señales de radiofrecuencia, y muchas compañías están insertando etiquetas en los productos, primero a nivel de palets para disponer de la trazabilidad del producto en su recorrido logístico, pero en breve comenzarán a nivel de unidades, de manera que en los centros comerciales se puedan aprovechar de este potencial.