
 La BH Europa, en general nos ha dejado muy buen sabor de boca, aunque no todo fueron peritas en dulce. La única nota negativa la trajo James Arlen, que a través de un seductor titulo SCADA and ICS for Security Experts tuvo a la audiencia expectante, esperando las últimas novedades sobre seguridad SCADA. Nada mas allá de la realidad, detrás de un gran orador —todo hay que reconocerlo— la conferencia no aportó novedad alguna, vertiente técnica, o aplicación interesante.
La BH Europa, en general nos ha dejado muy buen sabor de boca, aunque no todo fueron peritas en dulce. La única nota negativa la trajo James Arlen, que a través de un seductor titulo SCADA and ICS for Security Experts tuvo a la audiencia expectante, esperando las últimas novedades sobre seguridad SCADA. Nada mas allá de la realidad, detrás de un gran orador —todo hay que reconocerlo— la conferencia no aportó novedad alguna, vertiente técnica, o aplicación interesante.
Por el contrario, Manish Saindane de Attack and Defense Labs acudió con una propuesta sobre como atacar aplicaciones que utilizan objetos serializados en Java. Manish ha desarrollado un plugin para Burp que permite al Pentester editar objetos Java on the fly. La serialización de objetos Java es un protocolo implementado por Sun para convertir objetos en tramas de bytes, con el objetivo de guardarlos en disco o transmitirlos por la red. Este flujo de datos contiene la suficiente información para reconstruir el objeto original. A título informativo, la clase que puede instanciar objetos de este tipo son ObjectOutputStream y ObjectInputStream, cuyos métodos serializables son: readObject(), writeObject().
Cuando un objeto serializado es transmitido por la red se puede identificar por su cabecera con los bytes 0xac 0xed, aunque es posible que viaje comprimido en formato zip. Si el objeto es de tipo String, por ejemplo, éste vendrá codificado en UTF-8 modificado. El ataque funciona de la siguiente manera:
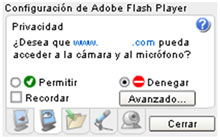
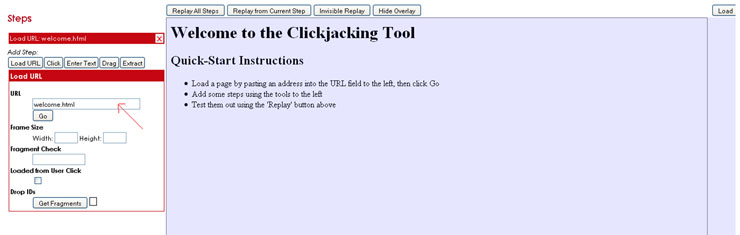
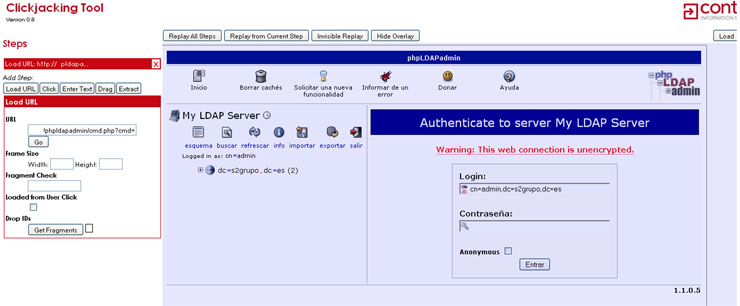
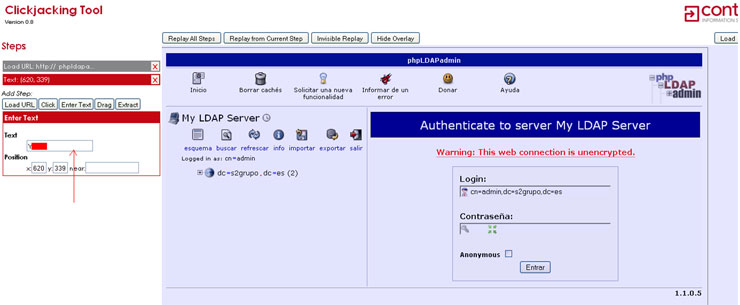
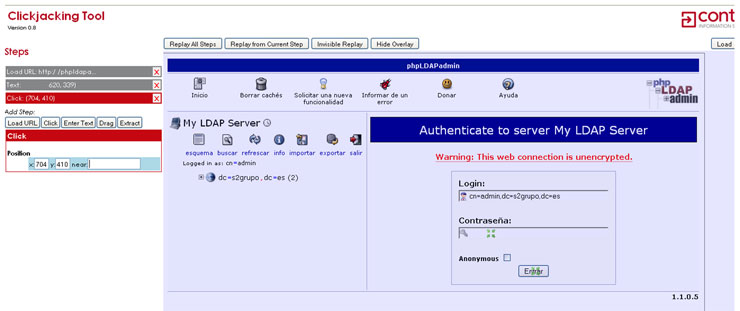
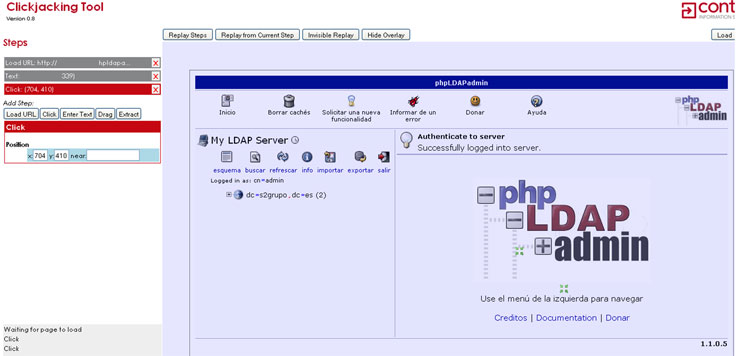
 Continuando con la crónica de la BH Europa, un magistral Christopher Tarnovsky vino a presentarnos Hacking Smartcards, un trabajo de más de seis meses que ha comenzado a dar sus frutos durante este último mes y que ha expuesto en exclusiva para la Black Hat.
Continuando con la crónica de la BH Europa, un magistral Christopher Tarnovsky vino a presentarnos Hacking Smartcards, un trabajo de más de seis meses que ha comenzado a dar sus frutos durante este último mes y que ha expuesto en exclusiva para la Black Hat.  Como era de esperar una de las conferencias de seguridad más importantes del mundo, la Black Hat, no ha defraudado en su vertiente europea. Un gran escenario, el Palau de Congresos de Catalunya, ha servido de perfecto telón de fondo para albergar a la crème de la crème de los profesionales de la seguridad mundial, es por eso que
Como era de esperar una de las conferencias de seguridad más importantes del mundo, la Black Hat, no ha defraudado en su vertiente europea. Un gran escenario, el Palau de Congresos de Catalunya, ha servido de perfecto telón de fondo para albergar a la crème de la crème de los profesionales de la seguridad mundial, es por eso que  El evento fue en su primer día inaugurado por Max Kelly, máximo responsable de seguridad del bien conocido portal social Facebook. Éste introdujo los valores de seguridad que son aplicados en su política y que muchos de nosotros en nuestras organizaciones deberíamos seguir. En primera instancia, según palabras de Max, Facebook persigue mediante su equipo legal a todo aquel atacante o intruso que realice acciones ilícitas contra sus sistemas, mediante la CAN-SPAM (15 USC 7701), Computer Security Fraud And Abuse Act (18 USC 1030) y evidentemente los Facebook’s Rights and Responsabilities. Para dar soporte a acciones técnicas se apoyan en la comunidad mundial de la seguridad White-Hats, analizando los ataques recibidos con el objetivo de conocer a tu enemigo. Por último hubo una frase de su presentación que debe incitar a la reflexión colectiva: Compliance isn’t security. Ahí queda eso.
El evento fue en su primer día inaugurado por Max Kelly, máximo responsable de seguridad del bien conocido portal social Facebook. Éste introdujo los valores de seguridad que son aplicados en su política y que muchos de nosotros en nuestras organizaciones deberíamos seguir. En primera instancia, según palabras de Max, Facebook persigue mediante su equipo legal a todo aquel atacante o intruso que realice acciones ilícitas contra sus sistemas, mediante la CAN-SPAM (15 USC 7701), Computer Security Fraud And Abuse Act (18 USC 1030) y evidentemente los Facebook’s Rights and Responsabilities. Para dar soporte a acciones técnicas se apoyan en la comunidad mundial de la seguridad White-Hats, analizando los ataques recibidos con el objetivo de conocer a tu enemigo. Por último hubo una frase de su presentación que debe incitar a la reflexión colectiva: Compliance isn’t security. Ahí queda eso. La esteganografía —del griego steganos (oculto) y graphos (escritura)—, en términos informáticos, es la disciplina que estudia el conjunto de técnicas cuyo fin es la ocultación de información sensible, mensajes u objetos, dentro de otros denominados ficheros contenedores, normalmente multimedia: imágenes digitales, vídeos o archivos de audio, con el objetivo de que la información pueda pasar inadvertida a terceros y sólo pueda ser recuperada por un usuario legítimo.
La esteganografía —del griego steganos (oculto) y graphos (escritura)—, en términos informáticos, es la disciplina que estudia el conjunto de técnicas cuyo fin es la ocultación de información sensible, mensajes u objetos, dentro de otros denominados ficheros contenedores, normalmente multimedia: imágenes digitales, vídeos o archivos de audio, con el objetivo de que la información pueda pasar inadvertida a terceros y sólo pueda ser recuperada por un usuario legítimo. {kind=link}