
(Aprovechando que estamos en Fallas, hoy les traemos una entrada sobre seguridad en Fallas, con su toque lúdico-festivo)
 Hace unos años durante una de las “Mascletàs” que se producen todos los días del mes de fallas a las 14h en la plaza del ayuntamiento de Valencia, unos delincuentes atracaron un banco cercano a la misma plaza, utilizando obviamente el ruido y las vibraciones producidos por la mascletà para camuflar el ruido producido por la alarma del banco (hay una leyenda urbana que dice que las oficinas bancarias de la zona desactivan sus alarmas durante la mascletà) y sus propias armas.
Hace unos años durante una de las “Mascletàs” que se producen todos los días del mes de fallas a las 14h en la plaza del ayuntamiento de Valencia, unos delincuentes atracaron un banco cercano a la misma plaza, utilizando obviamente el ruido y las vibraciones producidos por la mascletà para camuflar el ruido producido por la alarma del banco (hay una leyenda urbana que dice que las oficinas bancarias de la zona desactivan sus alarmas durante la mascletà) y sus propias armas.
Es poco probable que exista una alarma, sonora o silenciosa, que sea capaz de diferenciar entre una mascletà y un tiroteo; las alarmas de vibración quedan inutilizadas por las explosiones pirotécnicas y dado el gentío que se aglutina en la zona es fácil escabullirse entre la gente y pasar desapercibido.
Aunque las entidades bancarias hayan incluido mecanismos para dificultar los atracos, como cajas con apertura retardada y cajeros blindados, es imposible que se pudiera evitar un robo como ese; estoy convencido que las entidades bancarias simplemente confían en la estadísticas… y en cerrar a las 13h durante la “semana fallera” :-) para evitar los robos.
Otra de las cosas que trae el mes de fallas a Valencia son las calles cortadas pero cortadas de verdad; no es que alguien ponga una valla amarilla a la entrada de la calle, no. Es que además de las vallas amarillas, la calle tiene en el medio un monumento fallero, un escenario para las verbenas, dos churrerías y un casal fallero, así como varias decenas o centenas de vecinos disfrutando, cada uno a su manera, de la falla y de la fiesta.
 Como ya hemos comentado en
Como ya hemos comentado en  En esta entrada me voy a atrever a darles mi visión personal de las conclusiones que se extrajeron del taller “Gestión de Continuidad: Planes de Contingencia, Gestión de Crisis” del
En esta entrada me voy a atrever a darles mi visión personal de las conclusiones que se extrajeron del taller “Gestión de Continuidad: Planes de Contingencia, Gestión de Crisis” del  Estimados lectores, muy frecuentemente el primer pensamiento por parte de las empresas a la hora de afrontar la seguridad viene marcado por fuertes inversiones, como pueden ser costosas soluciones en infraestructura de red (IDS, Firewall), la compra de antivirus centralizados, suites de ServiceDesk, o laboriosos proyectos de consultoría. Si bien acometer dichas proyectos o compras de este tipo es un requisito para la consecución de cierto grado de seguridad empresarial, no resulta ser la panacea a la totalidad de los problemas de seguridad.
Estimados lectores, muy frecuentemente el primer pensamiento por parte de las empresas a la hora de afrontar la seguridad viene marcado por fuertes inversiones, como pueden ser costosas soluciones en infraestructura de red (IDS, Firewall), la compra de antivirus centralizados, suites de ServiceDesk, o laboriosos proyectos de consultoría. Si bien acometer dichas proyectos o compras de este tipo es un requisito para la consecución de cierto grado de seguridad empresarial, no resulta ser la panacea a la totalidad de los problemas de seguridad. Esta, entre otras, es una eterna cuestión que rodea a los datos personales y que nos da más de un dolor de cabeza: ¿es la IP un dato de carácter personal? Pues bien, todo parece apuntar, según lo que les mostraré en esta entrada, que sí. Yo, si les digo la verdad, siempre he sido un poco reacio a considerarla como tal, al menos en algunos ámbitos. Veamos un par de definiciones del Reglamento de Desarrollo de la LOPD:
Esta, entre otras, es una eterna cuestión que rodea a los datos personales y que nos da más de un dolor de cabeza: ¿es la IP un dato de carácter personal? Pues bien, todo parece apuntar, según lo que les mostraré en esta entrada, que sí. Yo, si les digo la verdad, siempre he sido un poco reacio a considerarla como tal, al menos en algunos ámbitos. Veamos un par de definiciones del Reglamento de Desarrollo de la LOPD: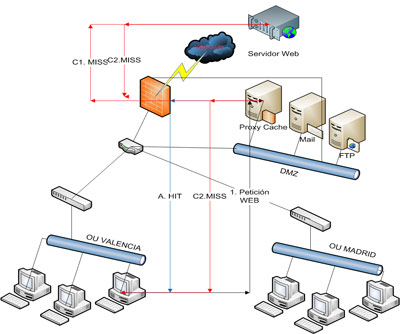 Como puede verse, en el mejor de los casos nos ahorramos el enrutamiento desde el proxy al servidor sobre el que se realiza la petición y la transferencia de la información solicitada a través de Internet, mientras que en el peor de los casos añadimos un salto más en el enrutamiento. Por supuesto, cuánto más accedido sea un determinado contenido por los usuarios de la red interna, mayor probabilidad de que el objeto se encuentre en cache y por tanto, mayor incremento del rendimiento del sistema.
Como puede verse, en el mejor de los casos nos ahorramos el enrutamiento desde el proxy al servidor sobre el que se realiza la petición y la transferencia de la información solicitada a través de Internet, mientras que en el peor de los casos añadimos un salto más en el enrutamiento. Por supuesto, cuánto más accedido sea un determinado contenido por los usuarios de la red interna, mayor probabilidad de que el objeto se encuentre en cache y por tanto, mayor incremento del rendimiento del sistema.