
 (N.d.E. Durante el fin de semana hemos estado haciendo algunos cambios en el blog, para lo que tuvimos que desactivar algunas funcionalidades. En cualquier caso, ahora todo debería funcionar correctamente)
(N.d.E. Durante el fin de semana hemos estado haciendo algunos cambios en el blog, para lo que tuvimos que desactivar algunas funcionalidades. En cualquier caso, ahora todo debería funcionar correctamente)
No hace falta que les hable sobre las ventajas de los snapshots. Tener una “foto” del servidor antes de hacer cualquier intervención crítica (o no tan crítica) en ella, es un valor por el que hubiésemos dado un brazo hace unos años. Con la difusión de la virtualización, esta práctica se ha vuelto mucho más común. La sencillez de hacer un simple “click” y tener las espaldas cubiertas hace que se llegue a utilizar más de lo necesario. Pero como casi todo en esta vida, los excesos se pagan. En ningún momento nuestra intención es desaconsejar su uso, al contrario, se pretende compartir errores y problemas tenidos para aprovechar al máximo y con seguridad esta gran herramienta.
La teoría del snapshot en un entorno virtual es sencilla. Cuando se lanza un snapshot, el disco virtual (vmdk) queda en un estado congelado, y se crea un nuevo disco virtual, separado del primero, donde se almacenan todos los cambios generados desde ese punto. Hay que tener cuidado al manejar estos “discos hijo”, intentar manipularlos o cambiar la configuración de estos vmdk, ya que esto puede ocasionar una pérdida total de datos.
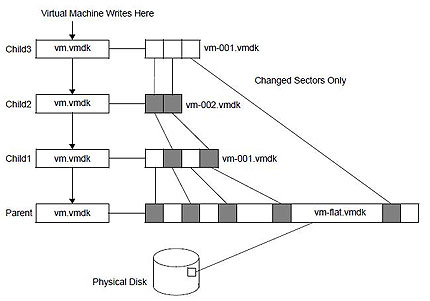 Otra cuestión a tomar en cuenta es la generación de snapshots sobre snapshots. Me explico con un ejemplo: antes de una intervención hemos generado un snapshot, todo ha ido bien, pero no lo borramos “por si acaso”. Al poco tiempo tenemos otra intervención en el mismo servidor, y generamos de nuevo otro snapshot. Esto es totalmente posible y se hace habitualmente, pero no creo que sea una práctica recomendable. El resultado es que se van generando “discos hijos”, cada uno con sus puntos de cambios, y al final el disco virtual inicial acaba siendo una segregación de ficheros, los cuales en caso de error son mucho más complicados de tratar. Personalmente, después de una intervención tras comprobar que todo ha ido bien siempre consolido los snapshots, con lo cual se vuelven a fundir los discos en uno sólo. Tal vez el gráfico que se muestra (fuente VmWare) ayude un poco más en la comprensión del problema.
Otra cuestión a tomar en cuenta es la generación de snapshots sobre snapshots. Me explico con un ejemplo: antes de una intervención hemos generado un snapshot, todo ha ido bien, pero no lo borramos “por si acaso”. Al poco tiempo tenemos otra intervención en el mismo servidor, y generamos de nuevo otro snapshot. Esto es totalmente posible y se hace habitualmente, pero no creo que sea una práctica recomendable. El resultado es que se van generando “discos hijos”, cada uno con sus puntos de cambios, y al final el disco virtual inicial acaba siendo una segregación de ficheros, los cuales en caso de error son mucho más complicados de tratar. Personalmente, después de una intervención tras comprobar que todo ha ido bien siempre consolido los snapshots, con lo cual se vuelven a fundir los discos en uno sólo. Tal vez el gráfico que se muestra (fuente VmWare) ayude un poco más en la comprensión del problema.
Pero esto no es todo. Uno de los descuidos más comunes es el llenado de los “datastores”, (donde se almacenan las máquinas virtuales) por culpa de estos snapshots. El espacio ocupado por un disco virtual en un datastore es un valor fijo, es decir, si tenemos libre 400Gb y montamos un servidor con un disco de 300Gb, el espacio libre en ese datastore será SIEMPRE de 100Gb. Pero ojo, una vez hagamos un snapshot de ese disco, el vmdk de 100Gb quedará congelado y se generará un nuevo disco donde se irán almacenando los nuevos cambios. Es decir, ese espacio libre que creíamos que teníamos puede llenarse y darnos una sorpresa. Una buena manera de evitar este problema es tener bien monitorizados los datastores de nuestra infraestructura, pero ese es un tema que trataremos en otra entrada….
 Una de las mejores definiciones que he leído de Seguridad es aquella que dice que la Seguridad es una sensación. Las personas tenemos la sensación de estar seguras o inseguras en base percepciones, estímulos que recibimos del entorno y que nos hacen sentirnos de esa manera.
Una de las mejores definiciones que he leído de Seguridad es aquella que dice que la Seguridad es una sensación. Las personas tenemos la sensación de estar seguras o inseguras en base percepciones, estímulos que recibimos del entorno y que nos hacen sentirnos de esa manera.