
Hace unos meses, después de la contratación de un servicio de “privacidad” para mi dominio personal (ya hablé de ello aquí), tuve un pequeño problema con el usuario y clave que me había sido asignado para la gestión del servicio, que imposibilitaba cualquier tipo de gestión, valga la redundancia. Después de obtener varias respuestas cíclicas y estériles, que sin duda estaban sacadas de algún procedimiento diseñado por idiotas (profundos), la empresa en cuestión me pide que mande un fax con mi fotografía sacada de algún documento oficial. Así que ante la falta de alternativas, ni corto ni perezoso, les mando una fotografía en blanco y negro, a lo que me contestan con lo siguiente:
We are not able to distinguish the identity of the person pictured on the photo id we received. Our legal department requires a clear, readable copy of government-issued photo identification in order for us to make any changes to an account.
[…]
 Las conclusiones sacadas de estos estudios (que no explicito de forma premeditada, disculpen los lectores la falta de pulcritud científica) otorgan unos niveles de seguridad en grandes, medianas y pequeñas empresas que, no es que disten de lo percibido en el dia a dia, es que parece que vengan de ese planeta con vida extraterrestre que aún siguen buscando los astrofísicos (y que gracias a estos estudios, ya sabemos que existe y dispone de un nivel tecnológico muy superior al nuestro).
Las conclusiones sacadas de estos estudios (que no explicito de forma premeditada, disculpen los lectores la falta de pulcritud científica) otorgan unos niveles de seguridad en grandes, medianas y pequeñas empresas que, no es que disten de lo percibido en el dia a dia, es que parece que vengan de ese planeta con vida extraterrestre que aún siguen buscando los astrofísicos (y que gracias a estos estudios, ya sabemos que existe y dispone de un nivel tecnológico muy superior al nuestro).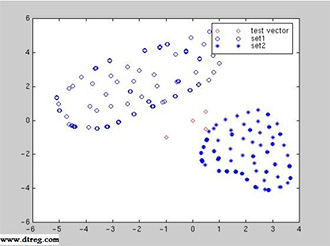 En general, podemos aproximar la problemática de detección heurística de software malicioso a un sistema de reconocimiento automático de patrones, similar al empleado por los sistemas antispam. De esta manera, dado un elemento a analizar, se extraerían N características a considerar, con sus valores correspondientes, definiendo por tanto para este elemento un punto en un espacio N-dimensional de elementos analizados. Si la heurística seleccionada fuera lo suficientemente adecuada, observariamos agrupaciones de elementos en este espacio, tal y como se puede apreciar en la gráfica.
En general, podemos aproximar la problemática de detección heurística de software malicioso a un sistema de reconocimiento automático de patrones, similar al empleado por los sistemas antispam. De esta manera, dado un elemento a analizar, se extraerían N características a considerar, con sus valores correspondientes, definiendo por tanto para este elemento un punto en un espacio N-dimensional de elementos analizados. Si la heurística seleccionada fuera lo suficientemente adecuada, observariamos agrupaciones de elementos en este espacio, tal y como se puede apreciar en la gráfica. Reconozco que soy “de la vieja escuela”, que me gusta “tocar papel” cuando tengo que revisar un informe o leer un documento mínimamente extenso (y tengo que reconocer que esto me provoca un conflicto con mi conciencia medioambiental, pero eso es otro tema…). Ese gusto por el papel hace que periódicamente —siguiendo la política de mesas limpias implantada en mi organización— tenga que hacer limpieza, y destruir adecuadamente la documentación obsoleta.
Reconozco que soy “de la vieja escuela”, que me gusta “tocar papel” cuando tengo que revisar un informe o leer un documento mínimamente extenso (y tengo que reconocer que esto me provoca un conflicto con mi conciencia medioambiental, pero eso es otro tema…). Ese gusto por el papel hace que periódicamente —siguiendo la política de mesas limpias implantada en mi organización— tenga que hacer limpieza, y destruir adecuadamente la documentación obsoleta.