
Cuando pasas mucho tiempo analizando muestras de malware empiezas a darte cuenta de que cada vez es más frecuente encontrarte con técnicas anti-sandboxing y anti-debugging. Estas técnicas tienen como finalidad proteger la muestra ante los análisis de malware dinámicos y evitar que su comportamiento sea estudiado.
Las técnicas anti-sandboxing se basan en encontrar alguna traza de información clave del sistema donde se está ejecutando. Esta información debería ser exclusiva de sistemas virtualizados, por ejemplo, claves concretas en el registro de una máquina virtual Windows, procesos de VMware o VirtualBox, tamaño del disco duro (en máquinas virtuales suele ser menor), etc.
Por otro lado, las técnicas anti-debugging son utilizadas por el malware para detectar si está siendo ejecutado desde un debugger. Generalmente, cuando detecta que es así, realiza acciones distintas al proceso de infección para el que ha sido programado, o bien, finaliza el proceso inmediatamente con el fin de complicar el análisis del mismo.
Muchas veces, ambas técnicas son incluidas en la misma muestra, incluso implementan varios métodos de cada técnica para protegerse mejor ante mirones.
La mayor parte de las técnicas anti-sandboxing pueden ser evadidas fácilmente por un analista de malware, por ejemplo, cerrando los procesos de las “tools” de la máquina virtual, cambiando de plataforma de virtualización, modificando algunas claves del registro, etc. En cambio, engañar al malware para que se ejecute correctamente en un debugger puede ser algo más complicado.
Vamos a detallar brevemente en que consisten algunas de estas técnicas. Además, crearemos pequeños “crackmes” con los que jugaremos a evadir las protecciones. Nosotros vamos a utilizar OllyDbg, pero podéis usar el que más os guste. Podéis echar un vistazo a la web de Ricardo Narvaja, donde podréis encontrar mucha información sobre el uso de este debugger y de cracking en general. Como la mayoría del malware está programado para plataformas Windows, nos basaremos en esta. Todos los que hayáis trabajado alguna vez con debuggers como OllyDbg, WindDbg, Radare o IDA ya sabréis que se requieren conocimientos sobre lenguaje ensamblador y estructuras internas de ficheros, así que os animo a que os documentéis al respecto.
Vamos a comenzar con una técnica anti-debugging muy fácil de implementar, pero también muy fácil de evadir, la función “IsDebuggerPresent”.
IsDebuggerPresent
Es una función de la librería kernel32.dll. Si el proceso está siendo debuggeado, la función devuelve un valor distinto de 0, en caso contrario, el valor devuelto es 0. Es muy fácil de implementar ya que basta con realizar la llamada a la función y comparar el valor devuelto. Podéis ver la documentación oficial aquí.
Esta función lo que realmente hace es consultar el valor del flag “BeingDebugged” del PEB (Process Environment Block), el cual se activa si el proceso está siendo debuggeado. Vamos a ponernos manos a la obra, podéis descargar el binario y los sources (lenguaje C) de este crackme desde mi cuenta de GitHub: https://github.com/reverc0de/saw-anti-debugging.
El código de crackme01_IsDebuggerPresent es el siguiente:
/***************************************************************** * File: crackme01_IsDebuggerPresent.c * Description: Es un crackme con la proteccion IsDebuggerPresent * Author: reverc0de * Date: 26/03/2015 * Github: https://github.com/reverc0de/saw-anti-debugging *****************************************************************/ #include#include int main(int argc, char **argv) { if (IsDebuggerPresent()) { MessageBox(0, "Debugger detectado!!","Crackme01 IsDebuggerPresent",MB_OK); exit(0); } MessageBox(0, "Debugger NO detectado!!","Crackme01 IsDebuggerPresent",MB_OK); return 0; }
Si deseáis, podéis compilarlo vosotros mismos en cualquier IDE para Windows como Dev-C++. Si ejecutamos el crackme directamente (crackme01_IsDebuggerPresent.exe), el mensaje es el esperado:

Ahora vamos a cargarlo en OllyDbg y lo ejecutamos con F9. Esta vez, el crackme ha detectado que se esta ejecutando a través de un debugger:

¿Y ahora que? ¿Como podemos saltarnos esta protección? Se puede conseguir de varias formas pero primero, hay que echar un vistazo al código en OllyDbg cuando llama a la función en cuestión:
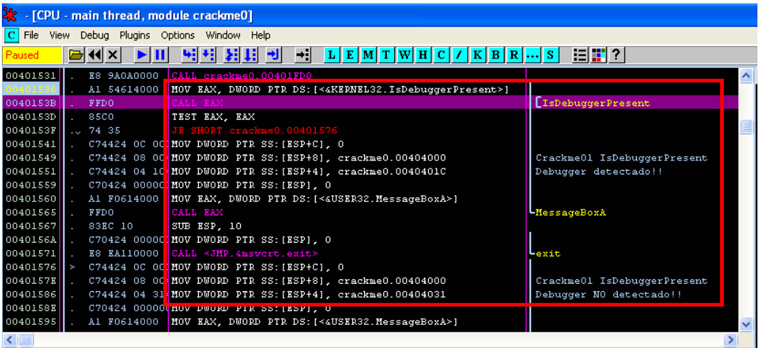
En el fragmento de código dentro del recuadro rojo encontramos la llamada a la función IsDebuggerPresent.
Después de la llamada tenemos una comparación con TEST del registro EAX. Con TEST comprobamos si el valor de EAX es igual a 0, en cuyo caso el flag ZF se pone a 1 y se ejecutaría el salto ‘JE SHORT‘ a la posición 00401576. Si ejecutamos el crackme paso a paso (F7), podemos ver como EAX tiene el valor 1 en la comparación y el salto no se produce (ZF = 0), continuando con la ejecución de código secuencial.
A continuación nos encontramos con la función MessageBoxA, la cual genera el mensaje que hemos visto anteriormente con el texto “Debugger detectado!!”. Si seguimos analizando unas líneas más, podemos ver como en la posición 00401576, a la cual se accedía desde la operación de salto anterior (JE), se encuentra otra llamada a MessageBoxA, pero esta vez con el texto del mensaje que deseamos, “Debugger NO detectado!!”.
Conseguir que muestre el segundo mensaje y saltarnos así esta protección es tan fácil como sustituir el tipo de salto condicional, por ejemplo, por un salto JNZ, que se produce si ZF = 0, es decir, si el resultado de la comparación anterior es distinta a 0.
Para modificar el código en el debugger, nos situamos sobre la sentencia del salto y pulsamos la barra espaciadora. Se abrirá un cuadro donde tenemos que sustituir JE por JNZ y aceptamos. Si ahora ejecutamos de nuevo el crackme con esta modificación, obtendremos el mensaje que queríamos, ya que esta vez escoge el salto, consiguiendo evadir esta técnica anti-debugging.
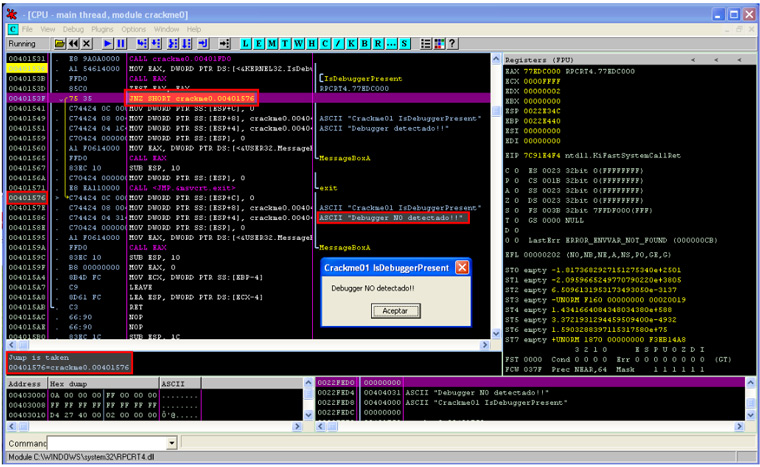
Otras formas de conseguir el mismo resultado es modificar el salto condicional por otro incondicional, o modificar el valor del flag Z en la ejecución del salto.
Variaciones de esta técnica anti-debugging puede ser la de consultar directamente el valor del flag “BeingDebugged” del PEB mediante la inserción de código ASM en el propio source del malware. Otra opción es utilizar la función CheckRemoteDebuggerPresent, que comprueba si el debugger se está ejecutando en otro proceso separado,utilizando además, la función IsDebuggerPresent.
Esta técnica anti-debugging es de las más obvias y fáciles de identificar por un analista de malware. En próximos artículos seguiremos jugando con otra técnicas algo más entretenidas así que… ¡empezad a practicar!
 Sin entrar en valoraciones sobre los motivos por los que en los últimos tiempos se crean “días de…” para todo, quiero hacer una mención al pasado día 31 de Marzo, cuando se celebró el día mundial de las copias de seguridad.
Sin entrar en valoraciones sobre los motivos por los que en los últimos tiempos se crean “días de…” para todo, quiero hacer una mención al pasado día 31 de Marzo, cuando se celebró el día mundial de las copias de seguridad.
 Desde que S2 Grupo comenzó su andadura hace ya unos cuantos años, los que formamos parte de ella hemos visto cómo años tras año ha sido
Desde que S2 Grupo comenzó su andadura hace ya unos cuantos años, los que formamos parte de ella hemos visto cómo años tras año ha sido