La pasada semana estuvimos mi compañero Amine y yo en el congreso de Seguridad RootedCON 2015 en Madrid. No hace falta que os hablemos de la importancia de estas conferencias a nivel nacional y, cada vez más, a nivel internacional (al menos en habla hispana).
Desde el pasado jueves 5 hasta el sábado 7, nos juntamos en el Centro de Congresos Príncipe Felipe unos cuantos compañeros de la profesión, estudiantes, cazatalentos de empresas de seguridad, miembros de las FCSE y todo tipo de “gente rarita” interesada por, sobretodo la Seguridad técnica, pero cada vez más presente, todo un abanico de diferentes tipos de seguridad.
Bueno, vamos al grano que hay mucha tela que cortar. Trataremos de haceros un breve resumen de cada una de las charlas a las que tuvimos la posibilidad de asistir, para que tengáis una idea de lo que se ha cocido este año por el congreso del candado.
 “La información es poder” es una frase célebre del filósofo inglés Francis Bacon, que a pesar de la distancia en el tiempo encaja a la perfección en la actualidad. Todo gira en torno a la información. Quedan ya pocas dudas sobre ello.
“La información es poder” es una frase célebre del filósofo inglés Francis Bacon, que a pesar de la distancia en el tiempo encaja a la perfección en la actualidad. Todo gira en torno a la información. Quedan ya pocas dudas sobre ello. A muchos de nosotros nos gustan los deportes de riesgo y qué mejor manera de demostrarlo que subirnos a un coche del que pensamos que tenemos el control pero que en realidad no es así. ¿Que tú quieres acelerar? Pues el coche decide frenar en seco… ¿que tienes frío? Vale, el coche te pone la calefacción a 30 grados y de ahí no baja. ¿No es un escenario fascinante?
A muchos de nosotros nos gustan los deportes de riesgo y qué mejor manera de demostrarlo que subirnos a un coche del que pensamos que tenemos el control pero que en realidad no es así. ¿Que tú quieres acelerar? Pues el coche decide frenar en seco… ¿que tienes frío? Vale, el coche te pone la calefacción a 30 grados y de ahí no baja. ¿No es un escenario fascinante? – Con este post me gustaría inaugurar una nueva sección en SAW llamada Barbarities, destinada a albergar cual pozo ciego, todas aquellas atrocidades que desde el punto de vista de seguridad uno ha ido viendo con el paso de los años. Se anima al lector a que comparta sus experiencias –
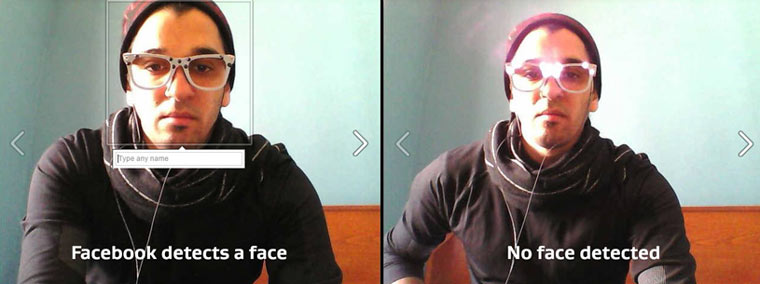
– Con este post me gustaría inaugurar una nueva sección en SAW llamada Barbarities, destinada a albergar cual pozo ciego, todas aquellas atrocidades que desde el punto de vista de seguridad uno ha ido viendo con el paso de los años. Se anima al lector a que comparta sus experiencias –  Como era de esperar, en el MWC de Barcelona se han presentado multitud de novedades en el mundo de la tecnología móvil, principalmente. Sin embargo, eventos previos a la apertura del MWC hay otros como es el MobileFocus. No voy a hablar de las últimas novedades de Samsung. Aquí el protagonista es… ¡AVG! Sí, sí, has leído bien, AVG. La compañía antivirus y su departamento de Innovación ha presentado en el MobileFocus unas gafas que te hacen invisible.
Como era de esperar, en el MWC de Barcelona se han presentado multitud de novedades en el mundo de la tecnología móvil, principalmente. Sin embargo, eventos previos a la apertura del MWC hay otros como es el MobileFocus. No voy a hablar de las últimas novedades de Samsung. Aquí el protagonista es… ¡AVG! Sí, sí, has leído bien, AVG. La compañía antivirus y su departamento de Innovación ha presentado en el MobileFocus unas gafas que te hacen invisible. Básicamente permite que, a la persona que lleva estas gafas, no se le pueda identificar mediante cámaras y otros sistemas de reconocimiento facial. Bueno, a quien se anime a llevarlas… más que nada porque son un poco feas. Pero, dejando de lado los aspectos estéticos, ¿cómo funcionan? Tal y como explica AVG funcionan gracias a dos principales materiales utilizados para su fabricación.
Básicamente permite que, a la persona que lleva estas gafas, no se le pueda identificar mediante cámaras y otros sistemas de reconocimiento facial. Bueno, a quien se anime a llevarlas… más que nada porque son un poco feas. Pero, dejando de lado los aspectos estéticos, ¿cómo funcionan? Tal y como explica AVG funcionan gracias a dos principales materiales utilizados para su fabricación.