Desde este post quiero presentar un poco más en detalle a una de las amigas de mi compañero Toni: INES.
Desde este post quiero presentar un poco más en detalle a una de las amigas de mi compañero Toni: INES.
INES es el acrónimo de Informe Nacional del Estado de Seguridad, pero más que un informe, se trata de una plataforma telemática que proporciona a las Administraciones Públicas un conocimiento más rápido e intuitivo de su nivel de adecuación al Esquema Nacional de Seguridad. INES, junto con la Guía CCN-STIC 824, Informe del Estado de Seguridad [PDF] servirán para elaborar el Informe Nacional del Estado de Seguridad.
Tal y como se indica en el propio manual de la plataforma, el encargado de acceder a la plataforma es el “Responsable de Seguridad”, por lo que todas las Administraciones Públicas deberían tener nombrado al correspondiente Responsable de Seguridad, para poder realizar las gestiones en la plataforma. Esta frase daría para otro post: ¿tienen todas las Administraciones Públicas un Responsable de Seguridad que ejerza realmente como tal?
El objetivo de la plataforma es doble. Por un lado sirve para que cada Administración Pública tenga un “sitio” donde pueda ir albergando, validando y analizando la información de seguridad propia de su organismo y consolidada a nivel de Administración Pública. Por otro lado, la herramienta permite que el CCN tenga acceso a través de un repositorio común a toda la información que ponen a su disposición todas las Administraciones Públicas, con lo que se da cumplimiento al artículo 35 que señala: “El Comité Sectorial de Administración Electrónica articulará los procedimientos necesarios para conocer regularmente el estado de las principales variables de la seguridad en los sistemas de información a los que se refiere el presente real decreto, de forma que permita elaborar un perfil general del estado de la seguridad en las Administraciones públicas“.
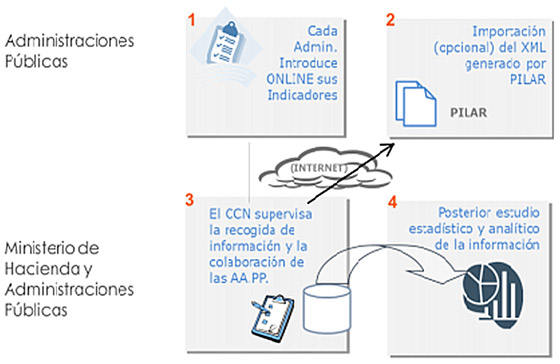
En junio de 2014 el Observatorio de Administración Electrónica elaboró una nota técnica sobre el seguimiento de la adecuación a los Esquemas Nacionales de Seguridad (ENS) y de Interoperabilidad (ENI). En ésta destaca el esfuerzo notable que han hecho las AA.PP para adaptarse a dichos esquemas como suele decirse, “con la que está cayendo”. También se resalta que pese al carácter voluntario de la incorporación de los datos por parte de las AAPP, ha habido una buena respuesta, especialmente por parte de la Administración General del Estado, seguida de las Comunidades Autónomas, Diputaciones y Ayuntamientos.
Según el informe, las Administraciones Públicas que han ofrecido sus datos voluntariamente están bastante avanzados en los aspectos relacionados con protección de instalaciones e infraestructuras, la protección de datos de carácter personal, la identificación de personas, las copias de seguridad, la política de seguridad y la identificación de Responsables de Seguridad y Sistemas. A la vista de los resultados, donde más “pinchan” es en los aspectos relacionados con la concienciación y la formación. El informe insiste en que es esencial que haya un Plan de Adecuación, un Responsable de Seguridad nombrado, se haya realizado una Categorización de los Sistemas y que se realice un Análisis de Riesgos.
No podemos acabar este post sin hacer algunas referencias. La primera a CLARA, otra de las amigas de Toni. CLARA es una herramienta creada por el CCN para analizar las características de seguridad técnica definidas en el Esquema Nacional de Seguridad. Dicho análisis de cumplimiento está basado en las normas de seguridad que han sido proporcionadas a través de la aplicación de plantillas de seguridad, según las guías CCN-STIC de la serie 800: 850A, 850B, 851A y 851B. La segunda referencia es a PILAR, una vieja conocida en el sector de la seguridad, que incorpora desde hace tiempo soporte para el ENS y mediante la que es posible realizar la valoración del cumplimiento de cada medida del Anexo II del ENS.
Acabaré diciendo que espero que el proyecto de modificación del ENS, cuya admisión de comentarios se cerró el pasado lunes 9 de febrero, no contradiga mucho de lo que he escrito. Si así fuese, me comprometo a explicar los cambios en un futuro post.

 Hace unas semanas se conoció que Google había dejado de desarrollar actualizaciones de seguridad para los sistemas Android cuya versión sea anterior a 4.4 (también denominada Kit Kat). Esto ha causado bastante revuelo ya que se trata de una decisión que afecta a la seguridad de más 900 millones de dispositivos, casi nada.
Hace unas semanas se conoció que Google había dejado de desarrollar actualizaciones de seguridad para los sistemas Android cuya versión sea anterior a 4.4 (también denominada Kit Kat). Esto ha causado bastante revuelo ya que se trata de una decisión que afecta a la seguridad de más 900 millones de dispositivos, casi nada.