
Para hoy tenemos una entrada de un nuevo colaborador, Alex Casanova, administrador de Sistemas Windows, Linux y Sistemas virtualizados con VMware con más de 10 años de experiencia. Adicto a las nuevas tecnologías y las telecomunicaciones dedica gran parte de su tiempo a la investigacion de sistemas radio, OSINT y redes de comunicaciones. Actualmente está involucrado en el despliegue de una red digital de comunicaciones DMR para radioaficionados. Se le puede encontrar en su twitter @hflistener y en su blog Digimodes.
Cada vez tenemos menos cables y más cosas que funcionan de forma inalámbrica. Las redes de comunicaciones inalámbricas están en auge; palabras como WiMAX, LTE, Wifi, TETRA, DMR son cada vez más comunes en nuestro vocabulario.
En el mundo de la seguridad, tradicionalmente se le había prestado especial atención a las comunicaciones que operan en las bandas ISM (libres) como WiFi o Bluetooth. Pero como se apuntaba en un post anterior, las investigaciones en el mundo de la seguridad están más centradas en el mundo de Internet y sus amenazas, dejando en un pequeño rincón a las comunicaciones inalámbricas.
 Estimados lectores, no se lleven a engaño por el título del post; no tengo tanto éxito con las mujeres como éste puede sugerir (ya me gustaría a mí). Tampoco guarda relación alguna con
Estimados lectores, no se lleven a engaño por el título del post; no tengo tanto éxito con las mujeres como éste puede sugerir (ya me gustaría a mí). Tampoco guarda relación alguna con 

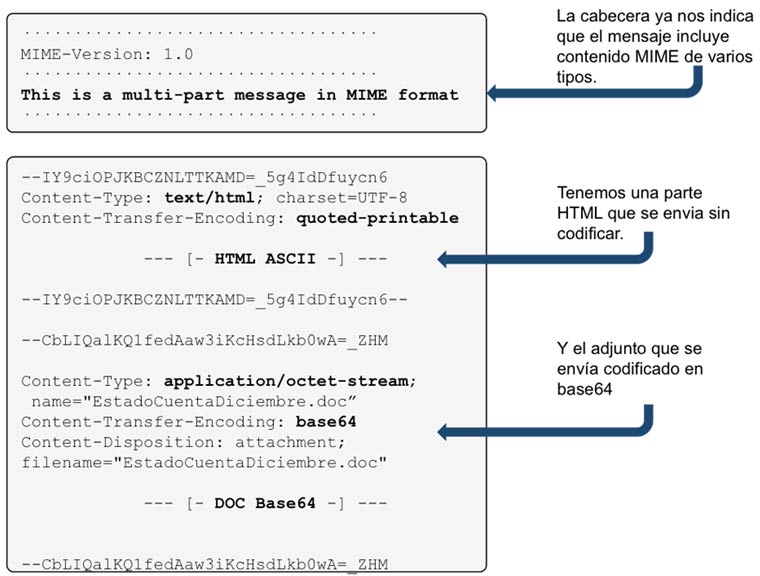
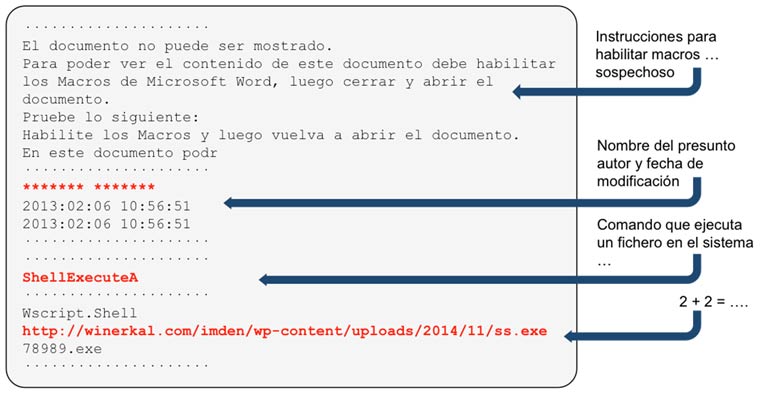

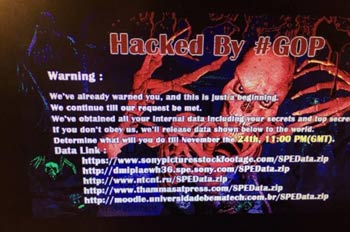 La nueva intrusión de la red interna de Sony no pasará a la historia por las técnicas utilizadas por los atacantes, ni por la dificultad en su ejecución, ni por el volumen de datos expuestos.
La nueva intrusión de la red interna de Sony no pasará a la historia por las técnicas utilizadas por los atacantes, ni por la dificultad en su ejecución, ni por el volumen de datos expuestos. 
