
 Hace un par de semanas llegó a mis oídos la existencia de una herramienta open source que nos puede ser útil a la hora de realizar las primeras fases de un pentesting: reconocimiento y mapping de servicios. Realizar estas primeros pasos de forma concienzuda puede hacer que las siguientes fases de nuestro pentesting puedan ser más dirigidas y eficaces a la hora de encontrar las posibles vulnerabilidades de nuestro objetivo.
Hace un par de semanas llegó a mis oídos la existencia de una herramienta open source que nos puede ser útil a la hora de realizar las primeras fases de un pentesting: reconocimiento y mapping de servicios. Realizar estas primeros pasos de forma concienzuda puede hacer que las siguientes fases de nuestro pentesting puedan ser más dirigidas y eficaces a la hora de encontrar las posibles vulnerabilidades de nuestro objetivo.
Spiderfoot, es una herramienta open source creada por Steve Micallef (@binarypool) que fue publicada por primera vez en el año 2005 y llegó a formar parte del temario de la certificación de hacking ético (CEH) durante 2009.
La primera versión estaba escrita en C#. A partir de ahí hubo un paréntesis de 7 años en su desarrollo hasta que en el 2012 el autor decidió retomar el proyecto y hacerla más portable, funcional y extensible, reescribiéndola enteramente en Python, dotándola de un interfaz web y almacenando los datos de los resultados en una base de datos SQlite3.
A día de hoy la versión publicada es la 2.1.5 y sigue en continua evolución y está disponible para Windows y para Linux.
Spiderfoot cuenta con varios módulos dedicados a recoger información y tratarla extrayendo datos relevantes de distintos ámbitos (dns, contenido web, whois, Virustotal, Shodan, etc.) que nos serán de utilidad a la hora de realizar tareas de OSINT (Open Source Intelligence).
Los módulos reciben ciertos elementos (URL, códigos http, direcciones de correo electrónico) en forma de eventos, y entonces actúan sobre ellos para que a su vez generen nuevos eventos que serán consumidos por otros módulos de la aplicación.
Entre los módulos disponibles, está sfp_dns que realiza búsquedas a partir de las ips/URLs introducidas, sobre servidores DNS obteniendo direcciones ip, registros MX/NS, etc. También cuenta con el módulo sfp_spider que inspeccionará todas las páginas de un sitio web extrayendo su contenido para usarlo en posteriores búsquedas.
Instalación
Si la instalamos sobre un sistema operativo Linux, la aplicación está escrita en Python 2.6-2.7, por lo que necesitaremos esta versión para ejecutar la aplicación, así como instalar las siguientes dependencias, que pueden ser instaladas usando el gestor de paquetes de Python PIP.
$sudo pip install lxml $sudo pip install netaddr $sudo pip install M2Crypto $sudo pip install cherrypy $sudo pip install mako
Una vez instaladas las dependencias descargaremos el código de la aplicación:
git clone https://github.com/smicallef/spiderfoot.git
Tras esto ejecutaremos la aplicación usando el interprete de Python. Si no especificamos el puerto en que estará escuchando el servidor como parámetro en el momento de la ejecución, por defecto lo hará en el puerto 5001/tcp:
cd spiderfoot/ $sudo python ./sf.py 127.0.0.1:6666
En caso de instalarlo sobre un sistema Windows, todas las dependencias vienen incluidas en el ejecutable de instalación. Una vez ejecutado el servidor podremos acceder al interfaz apuntando nuestro navegador a la ip y puerto seleccionado.
En la primera página podremos configurar los escaneos; spiderfoot proporciona un alto nivel de granularidad a la hora de seleccionar los campos sobre los que se recogerá información. Podremos seleccionarlos por elemento (Imagen 1) o por módulo (Imagen 2).
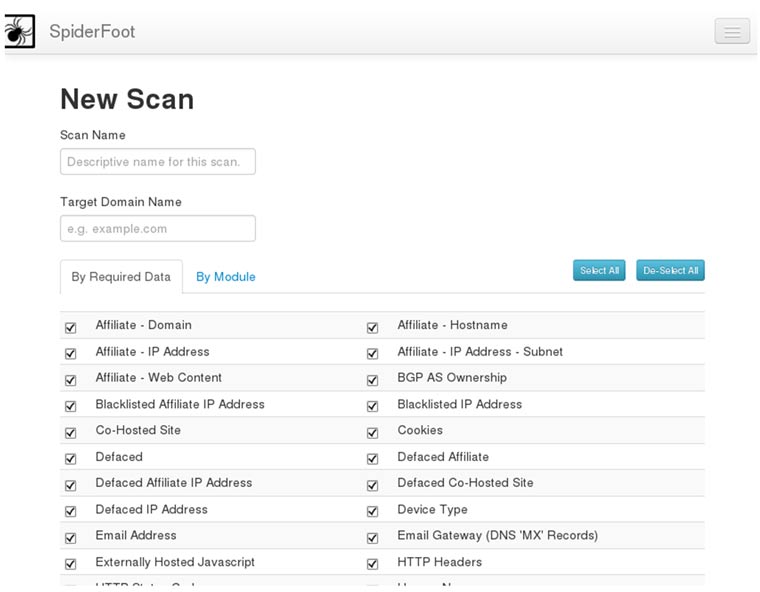
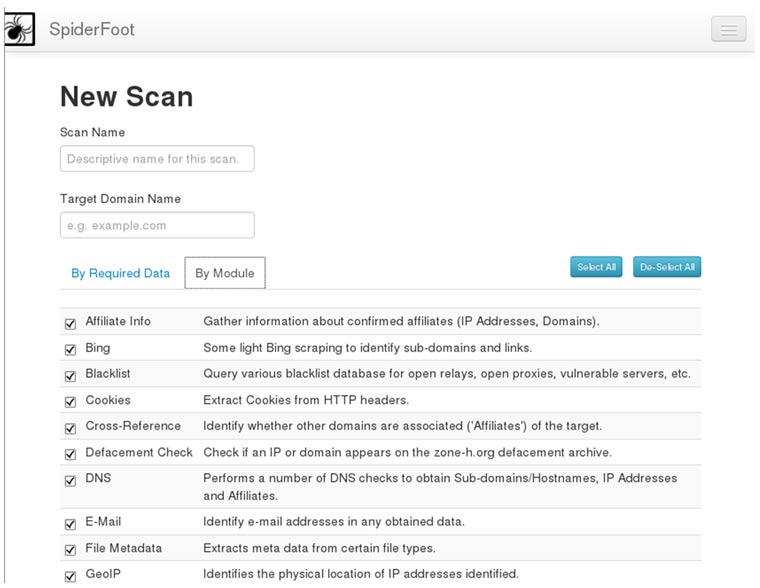
En el apartado de settings podremos configurar entre otro nuestra clave API de virus Total, Shodan, parámetros de las consultas DNS, puertos a escanear, y una multitud de opciones que iremos viendo más adelante.
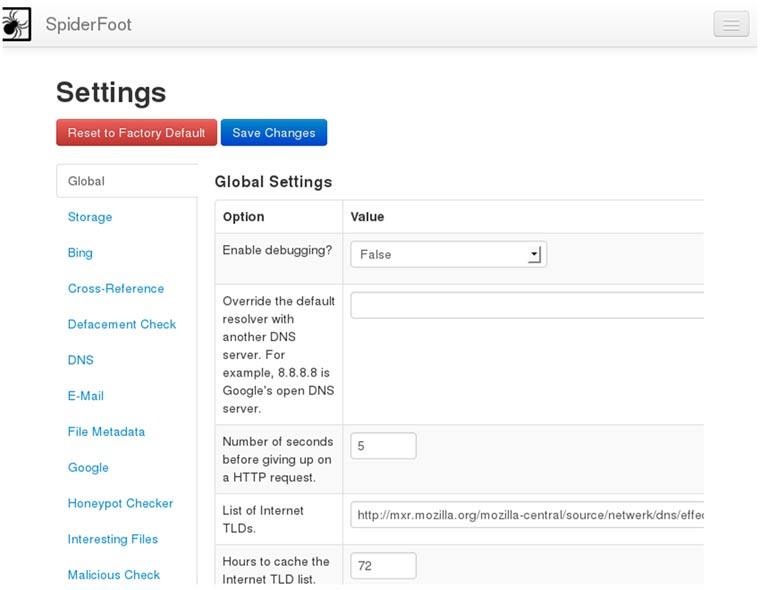
Y con esta breve introducción finaliza la primera parte. En siguientes artículos entraremos en profundidad en otros aspectos y utilidades de esta herramienta.
 Ya se ha hablado varias veces en este blog de las bondades que nos ofrece Python, se han recomendado lecturas y algunas librerías útiles en el mundo de la seguridad, pero como me considero una persona organizada y me gusta tener todo centralizado, inicio mis andadurías por este blog con una serie de artículos dedicados al uso de Python en el pentest.
Ya se ha hablado varias veces en este blog de las bondades que nos ofrece Python, se han recomendado lecturas y algunas librerías útiles en el mundo de la seguridad, pero como me considero una persona organizada y me gusta tener todo centralizado, inicio mis andadurías por este blog con una serie de artículos dedicados al uso de Python en el pentest.
 Bajo este título tan gore, quería comentar un
Bajo este título tan gore, quería comentar un  Un amigo mío tiene un amigo que es investigador experto en una de las principales instituciones de investigación francesas y le contaba, hace un par de días, que su grupo está preparando una propuesta para un proyecto de investigación junto con otros socios europeos, propuesta que debía presentarse esta semana.
Un amigo mío tiene un amigo que es investigador experto en una de las principales instituciones de investigación francesas y le contaba, hace un par de días, que su grupo está preparando una propuesta para un proyecto de investigación junto con otros socios europeos, propuesta que debía presentarse esta semana.