(Este artículo fue publicado previamente por José Rosell en la revista Economia3)
Es un hecho, y por tanto no vamos a extendernos en su justificación en estas líneas, que los procesos de negocio son altamente dependientes de la tecnología y que cada vez lo son más y no solo de la tecnología en sí misma, sino del uso que hacemos de ella.
En los últimos años hemos asistido asombrados al nacimiento y desarrollo vertiginoso de las redes sociales en el mundo. La rapidez de su expansión y su intensidad de uso, así como su importancia en todos los campos de nuestra sociedad, están obligando a organizaciones de todo el mundo a tomar cartas en el asunto. Por si fuera poco, la reciente proliferación de dispositivos móviles, “smartphones” y tabletas, que nos permiten un acceso ubicuo a la información, ha terminado de complicar el panorama desde el punto de vista de la gestión y el control de la información.
En 2008 el 45% de los internautas eran usuarios de redes sociales mientras que en 2011 lo son el 91%, de los que el 55% usan las redes sociales a través de dispositivos móviles. (Fuente: Observatorio de redes sociales del BBVA. IV Oleada. Abril de 2012)
Un factor adicional que hace más complicado el análisis del uso de las redes sociales y su impacto en nuestras organizaciones son los continuos vaivenes de su tipología y forma de uso, como se desprende del citado informe. Cuando empezamos a entender sus implicaciones y diseñamos una tímida pauta de actuación en esta materia, nos podemos encontrar con que su uso haya cambiado o “mutado” hasta el punto de dejar nuestras medidas obsoletas. No hay más que ver que, según el mismo estudio, en 2008, el uso de twitter entre los internautas apenas alcanzaba el 1% mientras que en 2011 la cifra de usuarios activos de twitter alcanzaba el 32%, cifra que se incrementa hasta el 51% si contamos usuarios que no se consideran especialmente activos en la red social.
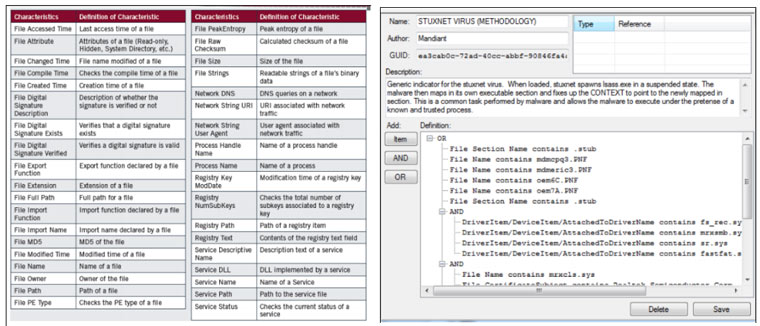
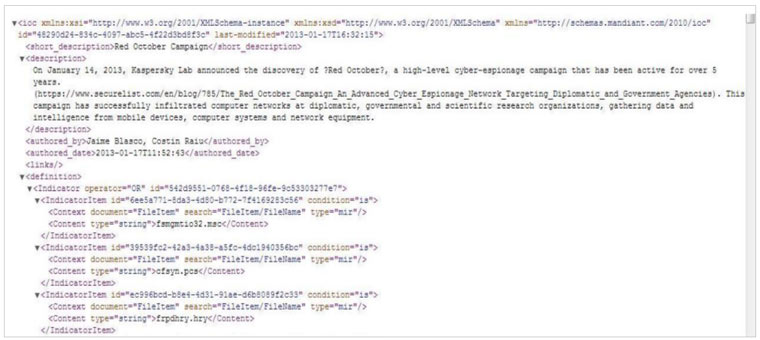
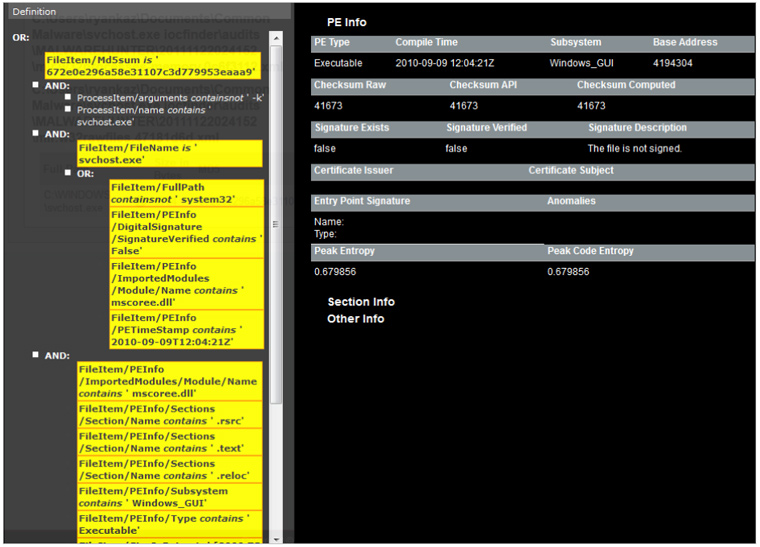
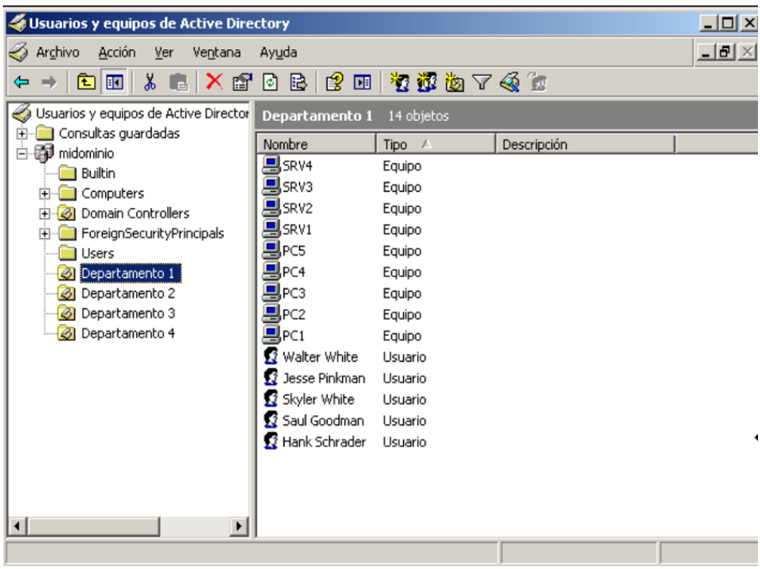
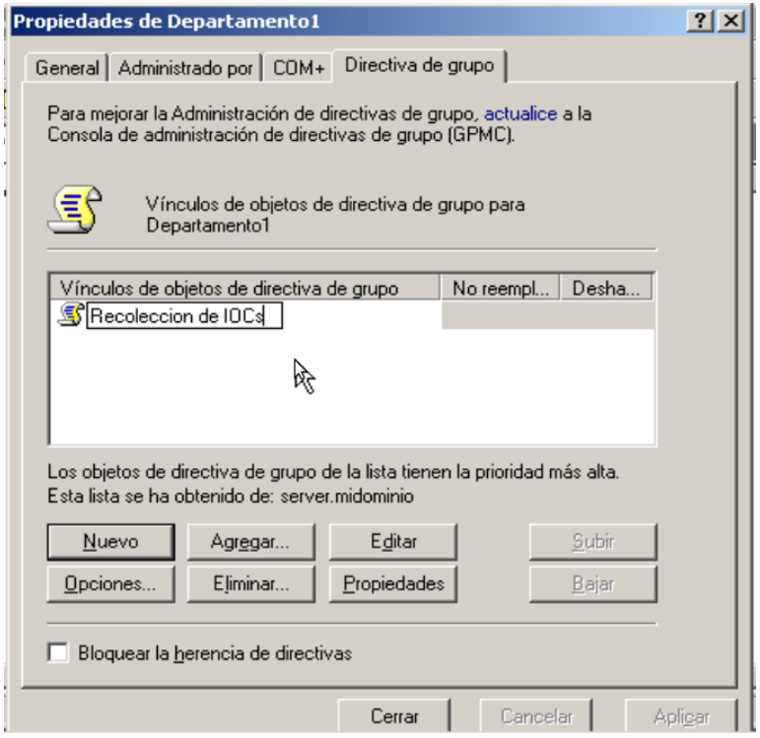
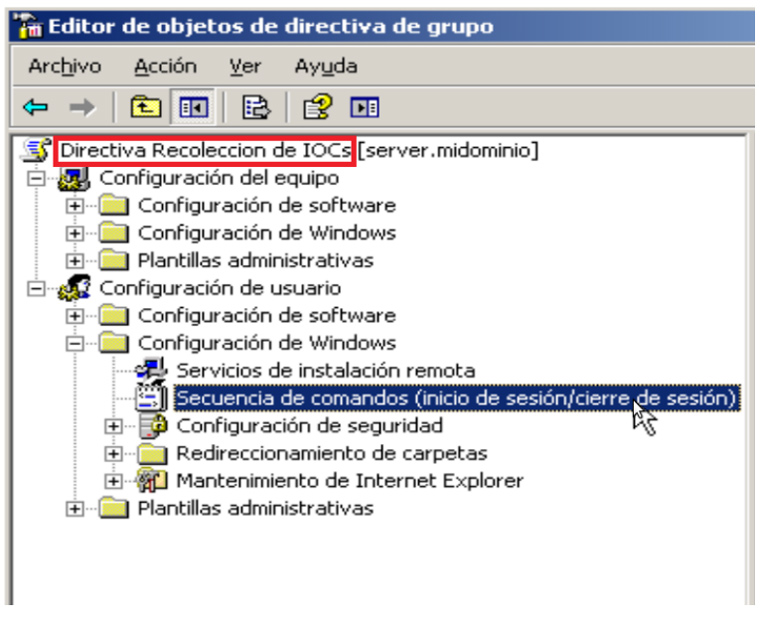
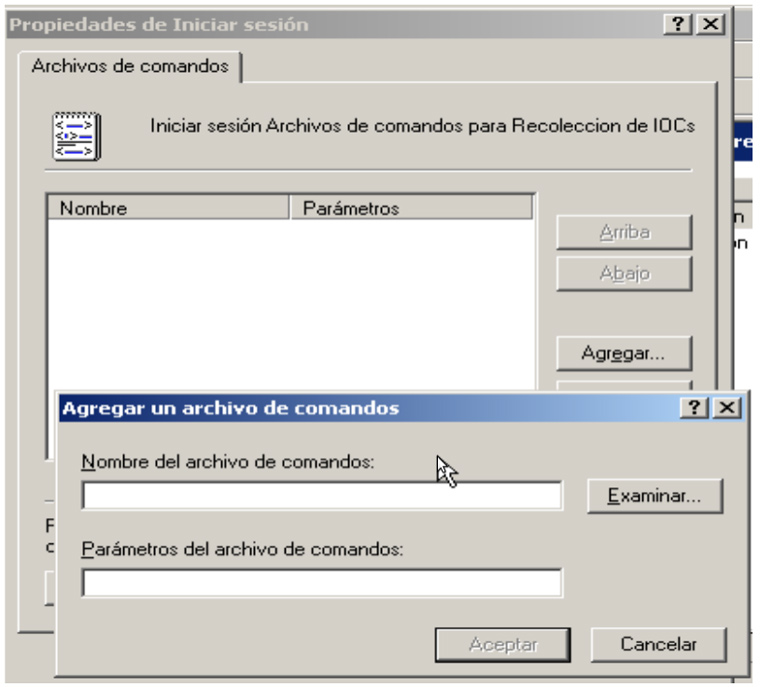
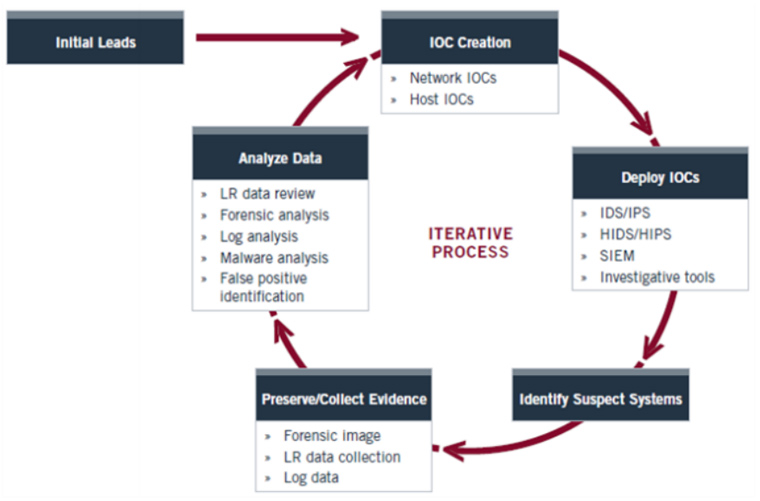 Este proceso puede ser muy lento si tenemos que ir equipo por equipo ejecutando el IOC Finder así que dependiendo de la infraestructura que haya o diseño de la red podemos pensar en automatizar este proceso ayudándonos de ciertas infraestructuras.
Este proceso puede ser muy lento si tenemos que ir equipo por equipo ejecutando el IOC Finder así que dependiendo de la infraestructura que haya o diseño de la red podemos pensar en automatizar este proceso ayudándonos de ciertas infraestructuras.